
আমাদের ডিজিটাল বিশ্বে, ব্যবসাগুলি প্রতিদিন প্রচুর ডেটা প্রক্রিয়া করে। ডেটা সংস্থাকে সচল রাখে এবং এটিকে আরও ভাল-অবহিত সিদ্ধান্ত নিতে সাহায্য করে। ব্যবসাগুলি নথিতে প্লাবিত হয়, কর্মচারীরা নতুন তৈরি করা থেকে শুরু করে বিভিন্ন উত্স যেমন ইমেল, পোর্টাল, চালান, রসিদ, আবেদন, প্রস্তাব, দাবি এবং আরও অনেক কিছু থেকে সংস্থায় প্রবেশ করা নথিগুলি।
কেউ এই নথিগুলি পর্যালোচনা না করা পর্যন্ত, একটি নির্দিষ্ট নথিটি কী সম্পর্কে বা এটি প্রক্রিয়া করার সর্বোত্তম উপায় তা জানার কোনও উপায় নেই৷ যাইহোক, প্রতিটি নথি কোথায় এবং কীভাবে সংরক্ষণ করা উচিত তা জানতে ম্যানুয়ালি প্রক্রিয়া করা কঠিন।
আসুন আমরা নথির শ্রেণীবিভাগ অন্বেষণ করি, কেন নথির শ্রেণীবিভাগ একটি ব্যবসার জন্য অত্যন্ত গুরুত্বপূর্ণ, এবং কীভাবে কম্পিউটার দৃষ্টি, প্রাকৃতিক ভাষা প্রক্রিয়াকরণ, এবং অপটিক্যাল ক্যারেক্টার রিকগনিশন ডকুমেন্ট শ্রেণীবিভাগ বা নথি প্রক্রিয়াকরণে একটি ভূমিকা পালন করে তা অধ্যয়ন করি।
নথি শ্রেণীবিভাগ কি?
ম্যানুয়াল ডকুমেন্টের শ্রেণীবিভাগের কাজগুলি অনেক ব্যবসার জন্য একটি বিশাল বাধা হতে পারে কারণ সেগুলি সময়সাপেক্ষ, ত্রুটি-প্রবণ এবং সম্পদ গ্রহণকারী। যখন NLP এবং ML-এর উপর ভিত্তি করে স্বয়ংক্রিয় শ্রেণীবিভাগের মডেলগুলি ব্যবহার করা হয়, তখন একটি নথির পাঠ্য স্বয়ংক্রিয়ভাবে চিহ্নিত, ট্যাগ করা এবং শ্রেণীবদ্ধ করা হয়।
নথির শ্রেণীবিভাগের কাজগুলি সাধারণত দুটি শ্রেণিবিন্যাসের উপর ভিত্তি করে করা হয়: পাঠ্য এবং ভিজ্যুয়াল। পাঠ্য শ্রেণিবিন্যাস বিষয়বস্তুর জেনার, থিম বা প্রকারের উপর ভিত্তি করে। ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং পাঠ্যের ধারণা, আবেগ এবং প্রসঙ্গ বোঝার জন্য ব্যবহৃত হয়। কম্পিউটার ভিশন এবং ইমেজ রিকগনিশন সিস্টেম ব্যবহার করে নথিতে উপস্থিত ভিজ্যুয়াল স্ট্রাকচারাল উপাদানগুলির উপর ভিত্তি করে ভিজ্যুয়াল শ্রেণীবিভাগ করা হয়।
কেন ব্যবসার নথির শ্রেণীবিভাগ প্রয়োজন?

প্রতিটি ব্যবসা, বড় এবং ছোট, তার দৈনন্দিন ক্রিয়াকলাপ পরিচালনা করতে ডকুমেন্টেশন মোকাবেলা করতে হবে। যেহেতু প্রতিটি নথিকে ম্যানুয়ালি প্রক্রিয়া করা অসম্ভব, তাই একটি স্বয়ংক্রিয় নথির শ্রেণিবিন্যাস ব্যবস্থা নিযুক্ত করা প্রয়োজন। নথির শ্রেণিবিন্যাস ব্যবস্থা ব্যবসায়িকদের বিষয়বস্তু সংগঠিত করতে এবং যে কোনো সময় এটি উপলব্ধ করার অনুমতি দেয়।
নথির শ্রেণীবিভাগে হাসপাতাল থেকে শুরু করে ব্যবসায়িক বিভিন্ন শিল্পে বেশ কিছু ব্যবহারের ক্ষেত্রে রয়েছে।
- এটি ব্যবসাগুলিকে নথি ব্যবস্থাপনা এবং প্রক্রিয়াকরণ স্বয়ংক্রিয় করতে সহায়তা করে।
- নথির শ্রেণীবিভাগ একটি জাগতিক এবং পুনরাবৃত্তিমূলক কাজ, প্রক্রিয়াটি স্বয়ংক্রিয়ভাবে প্রক্রিয়াকরণের ত্রুটি হ্রাস করে এবং পরিবর্তনের সময়কে উন্নত করে।
- নথিগুলির অটোমেশন দক্ষতা, নির্ভরযোগ্যতা এবং মাপযোগ্যতাও উন্নত করে।
নথি শ্রেণীবিভাগ বনাম. পাঠ্য শ্রেণিবিন্যাস
টেক্সট শ্রেণীবিভাগ এবং নথি শ্রেণীবিভাগ কখনও কখনও বিনিময়যোগ্যভাবে ব্যবহৃত হয়। যদিও উভয়ের মধ্যে খুব সামান্য পার্থক্য রয়েছে, তবে তারা কীভাবে আলাদা তা জানা গুরুত্বপূর্ণ।
পাঠ্য শ্রেণিবিন্যাস টেক্সট-ভিত্তিক নথিতে টেক্সট বিশ্লেষণ করার কৌশল নিয়োগ করা সম্পর্কে। পাঠ্যকে বিভিন্ন স্তরে শ্রেণীবদ্ধ করা যেতে পারে, যেমন
| সেন্টেন্স লেভেল | সাব-সেন্টেন্স লেভেল |
|---|---|
| পাঠ্য শ্রেণীবিভাগ একটি একক বাক্যে তথ্যের উপর ভিত্তি করে। | উপ-বাক্য স্তর বাক্যের মধ্যে থেকে উপ-অভিব্যক্তি আঁকে। |
| অনুচ্ছেদ স্তর | ডকুমেন্ট লেভেল |
|---|---|
| একটি একক অনুচ্ছেদ থেকে মূল বা সবচেয়ে গুরুত্বপূর্ণ তথ্য বের করে। | পুরো নথি থেকে গুরুত্বপূর্ণ তথ্য আঁকুন। |
টেক্সট শ্রেণীবিভাগ হল নথির শ্রেণীবিভাগের একটি উপসেট যা কোনো প্রদত্ত নথিতে পাঠ্যকে শ্রেণীবদ্ধ করার সাথে সম্পূর্ণভাবে কাজ করে। যদিও পাঠ্য শ্রেণিবিন্যাস শুধুমাত্র পাঠ্যের সাথে সম্পর্কিত, নথি শ্রেণীবিভাগ পাঠ্য এবং চাক্ষুষ উভয়ই। টেক্সট শ্রেণীবিভাগে, শুধুমাত্র টেক্সট শ্রেণীবদ্ধ করতে ব্যবহৃত হয়, যেখানে, নথি শ্রেণীবিভাগে, সম্পূর্ণ নথিটি প্রসঙ্গের জন্য ব্যবহার করা যেতে পারে।
কিভাবে নথি শ্রেণীবিভাগ কাজ করে?
নথির শ্রেণীবিভাগ দুটি পদ্ধতি ব্যবহার করে করা যেতে পারে: ম্যানুয়াল এবং স্বয়ংক্রিয়। ম্যানুয়াল শ্রেণীবিভাগে, একজন মানব ব্যবহারকারীকে অবশ্যই নথি পর্যালোচনা করতে হবে, ধারণাগুলির মধ্যে সম্পর্ক খুঁজে বের করতে হবে এবং সেই অনুযায়ী শ্রেণীবদ্ধ করতে হবে। স্বয়ংক্রিয় নথি শ্রেণীবিভাগে, মেশিন লার্নিং এবং গভীর শিক্ষার কৌশল ব্যবহার করা হয়। চলুন ব্যবসায়িক প্রক্রিয়ার বিভিন্ন ধরনের নথি বোঝার মাধ্যমে নথির শ্রেণীবিভাগের পদ্ধতিগুলো উন্মোচন করি।
স্ট্রাকচার্ড ডকুমেন্টস
একটি নথিতে ধারাবাহিক সংখ্যা এবং ফন্ট সহ ভাল-ফরম্যাট করা ডেটা থাকে। নথির বিন্যাসটিও সামঞ্জস্যপূর্ণ এবং এতে বিচ্যুতি নেই। এই ধরনের কাঠামোগত নথিগুলির জন্য শ্রেণীবিভাগের সরঞ্জাম তৈরি করা সহজ এবং অনুমানযোগ্য।
অসংগঠিত নথি
একটি অসংগঠিত নথিতে একটি অ-গঠিত বা খোলা বিন্যাসে উপস্থাপিত বিষয়বস্তু রয়েছে। উদাহরণের মধ্যে রয়েছে চিঠি, চুক্তি এবং আদেশ। যেহেতু তারা অসামঞ্জস্যপূর্ণ, এটি সমালোচনামূলক তথ্য সনাক্ত করা চ্যালেঞ্জিং হয়ে ওঠে।

নথি শ্রেণীবিভাগ কৌশল?
স্বয়ংক্রিয় নথির শ্রেণিবিন্যাস শ্রেণীকরণ প্রক্রিয়াকে সরল, স্বয়ংক্রিয় এবং গতি বাড়ানোর জন্য মেশিন লার্নিং এবং প্রাকৃতিক ভাষা প্রক্রিয়াকরণ কৌশল ব্যবহার করে। মেশিন লার্নিং নথির শ্রেণিবিন্যাসকে কম কষ্টকর, দ্রুত, আরও নির্ভুল, মাপযোগ্য এবং নিরপেক্ষ করে তোলে।
নথি শ্রেণীবিভাগ তিনটি কৌশল ব্যবহার করে করা যেতে পারে. তারা
নিয়ম-ভিত্তিক কৌশল
নিয়ম-ভিত্তিক কৌশলটি ভাষাগত নিদর্শন এবং নিয়মগুলির উপর ভিত্তি করে যা মডেলকে নির্দেশাবলী প্রদান করে। টেক্সট ট্যাগ করার জন্য মডেলগুলিকে ভাষা নিদর্শন, রূপবিদ্যা, বাক্য গঠন, শব্দার্থবিদ্যা এবং আরও অনেক কিছু সনাক্ত করতে প্রশিক্ষিত করা হয়। এই কৌশলটি ক্রমাগত উন্নত করা যেতে পারে, নতুন নিয়ম যোগ করা যেতে পারে এবং সঠিক অন্তর্দৃষ্টি বের করার জন্য উন্নত করা যেতে পারে। যাইহোক, এই কৌশলটি সময়সাপেক্ষ, আনস্কেলযোগ্য এবং জটিল হতে পারে।
তত্ত্বাবধানে শেখার
তত্ত্বাবধানে শিক্ষার মধ্যে ট্যাগের একটি সেট সংজ্ঞায়িত করা হয়, এবং বেশ কয়েকটি পাঠ্য ম্যানুয়ালি ট্যাগ করা হয় যাতে মেশিন লার্নিং সিস্টেম সঠিক ভবিষ্যদ্বাণী করা শিখতে পারে। অ্যালগরিদম ম্যানুয়ালি ট্যাগ করা নথির সেটে প্রশিক্ষিত। আপনি সিস্টেমে যত বেশি ডেটা ফিড করবেন, ফলাফল তত ভাল হবে। উদাহরণস্বরূপ, যদি টেক্সট বলে, 'পরিষেবাটি সাশ্রয়ী ছিল,' ট্যাগটি 'মূল্য'-এর অধীনে থাকা উচিত। মডেলের প্রশিক্ষণ সম্পূর্ণ হলে, এটি স্বয়ংক্রিয়ভাবে অদেখা নথিগুলির পূর্বাভাস দিতে পারে।
অশিক্ষিত শিক্ষা
তত্ত্বাবধানহীন শিক্ষায়, অনুরূপ নথিগুলিকে বিভিন্ন ক্লাস্টারে গোষ্ঠীভুক্ত করা হয়। এই শিক্ষার জন্য কোন পূর্ব জ্ঞানের প্রয়োজন হয় না। নথিগুলি ফন্ট, থিম, টেমপ্লেট এবং আরও অনেক কিছুর উপর ভিত্তি করে শ্রেণীবদ্ধ করা হয়। যদি নিয়মগুলি পূর্ব-সংজ্ঞায়িত, টুইক করা এবং নিখুঁত করা হয়, তাহলে এই মডেলটি নির্ভুলতার সাথে শ্রেণীবিভাগ প্রদান করতে পারে।
নথি শ্রেণীবিভাগ প্রক্রিয়া
একটি স্বয়ংক্রিয় নথির শ্রেণিবিন্যাস অ্যালগরিদম তৈরি করা গভীর শিক্ষা এবং মেশিন লার্নিং কর্মপ্রবাহ জড়িত।
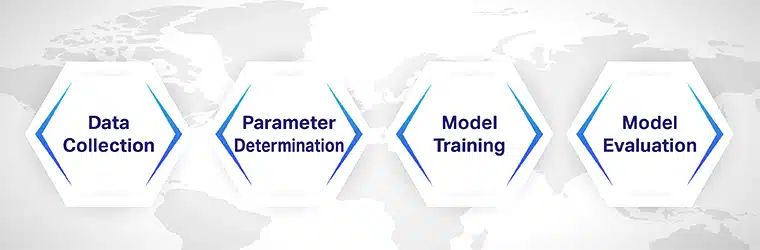
ধাপ 1: ডেটা সংগ্রহ
তথ্য সংগ্রহ ডকুমেন্ট ক্লাসিফিকেশন অ্যালগরিদম প্রশিক্ষণের জন্য সম্ভবত সবচেয়ে গুরুত্বপূর্ণ পদক্ষেপ। বিভিন্ন বিভাগ থেকে নথি সংগ্রহ করা প্রয়োজন যাতে অ্যালগরিদম কীভাবে তাদের শ্রেণীবদ্ধ করতে হয় তা শিখতে পারে।
উদাহরণস্বরূপ, যদি আপনার মডেলটিকে পাঁচটি ভিন্ন বিভাগে শ্রেণীবদ্ধ করার প্রয়োজন হয়, তাহলে আপনার কাছে একটি ডেটাসেট থাকতে হবে যাতে প্রতি বিভাগে ন্যূনতম 300টি নথি রয়েছে৷
এছাড়াও, প্রশিক্ষণের জন্য আপনি যে ডেটাসেটটি ব্যবহার করছেন তা সঠিকভাবে ট্যাগ করা হয়েছে তা নিশ্চিত করুন। ডেটাসেটটি ভুল হলে, আপনি যে মডেলটি তৈরি করবেন সেটি সমস্যায় পড়বে।
ধাপ 2: পরামিতি নির্ধারণ
মডেল প্রশিক্ষণের আগে, আপনাকে অবশ্যই মেশিন লার্নিং মডেলগুলিকে প্রশিক্ষণের জন্য পরামিতিগুলি নির্ধারণ করতে হবে। এই পর্যায়ে আপনি যে মেট্রিকগুলি সংজ্ঞায়িত করেছেন তা মডেলটিকে এর ভবিষ্যদ্বাণীতে আরও নির্ভুল এবং নির্ভরযোগ্য করতে সংশোধন করা যেতে পারে।
ধাপ 3: মডেল প্রশিক্ষণ
পরামিতি সেট করার পরে, মডেলকে প্রশিক্ষণ দিতে হবে। আপনি যদি সবেমাত্র মডেল ডেভেলপমেন্টের সাথে শুরু করছেন, আপনি প্রশিক্ষণ এবং পরীক্ষার উদ্দেশ্যে ওপেন-সোর্স ডেটাসেট ব্যবহার করার চেষ্টা করতে পারেন।
যদি মডেলটি সাধারণত একটি মেশিন লার্নিং অ্যালগরিদমের সাথে কাজ করে, আপনি মডেলটি আমদানি করতে পারেন বা অ্যালগরিদমের যুক্তির উপর ভিত্তি করে কোডিং করতে পারেন৷
ধাপ 4: মডেল মূল্যায়ন
প্রশিক্ষণের পরে মডেলটির কার্যকারিতা এবং নির্ভুলতা বাড়ানোর জন্য মূল্যায়ন করা অপরিহার্য। ডেটাসেটটিকে দুটি বিস্তৃত বিভাগে ভাগ করে শুরু করুন, একটি প্রশিক্ষণের জন্য এবং অন্যটি পরীক্ষার জন্য। মডেলের প্রশিক্ষণের জন্য ডেটাসেটের 70% এবং বাকি 30% পরীক্ষা এবং মূল্যায়নের জন্য ব্যবহার করুন।
বাস্তব জীবনের ব্যবহারের কেস
নথির শ্রেণীবিভাগ বিভিন্ন ব্যবসায়িক সমস্যা সমাধানের জন্য ব্যবহার করা হচ্ছে। যদিও বেশিরভাগ ব্যবহারের ক্ষেত্রে শ্রেণীবিভাগের কাজ নয়, অ্যালগরিদম নিজেকে বাস্তব জীবনের বিভিন্ন সমস্যা সমাধানের জন্য নিযুক্ত করে।
স্প্যাম সনাক্তকরণ
নথি শ্রেণীবিভাগ, বিশেষ করে পাঠ্য শ্রেণীবিভাগ, অবাঞ্ছিত স্প্যাম সনাক্ত করতে ব্যবহৃত হয়। বার্তাটি স্প্যাম কিনা তা নির্ধারণ করতে মডেলটিকে স্প্যাম বাক্যাংশ এবং তাদের ফ্রিকোয়েন্সি সনাক্ত করতে প্রশিক্ষণ দেওয়া হয়। উদাহরণ স্বরূপ, Google-এর Gmail স্প্যাম ডিটেক্টর প্রাকৃতিক ভাষা প্রক্রিয়াকরণ কৌশল ব্যবহার করে জাঙ্ক বার্তাগুলিতে ঘন ঘন ঘটতে থাকা শব্দগুলি সনাক্ত করতে এবং সঠিক ফোল্ডারে মেলটি ফেলে দেয়৷
অনুভূতির বিশ্লেষণ
সামাজিক শোনার মাধ্যমে অনুভূতি বিশ্লেষণ ব্যবসায়িকদের তাদের গ্রাহকদের, তাদের মতামত এবং তাদের পর্যালোচনা বুঝতে সাহায্য করে। পর্যালোচনা, প্রতিক্রিয়া, এবং অভিযোগগুলিকে শ্রেণিবদ্ধ করে এবং তাদের মানসিক প্রকৃতির উপর ভিত্তি করে শ্রেণীবদ্ধ করে, NLP-ভিত্তিক মডেলগুলি অনুভূতি বিশ্লেষণে সহায়তা করে। মডেলটিকে ইতিবাচক বা নেতিবাচক অর্থ বোঝানো বা আছে এমন শব্দগুলি বের করতে প্রশিক্ষিত করা হয়।
টিকিট বা অগ্রাধিকার শ্রেণীবিভাগ
যেকোনো ব্যবসার গ্রাহক পরিষেবা বিভাগ অনেক পরিষেবার অনুরোধ এবং টিকিট জুড়ে আসে। একটি স্বয়ংক্রিয় নথি শ্রেণীবিন্যাস টুল টিকিটের বিশাল পরিমাণের মধ্য দিয়ে যেতে সাহায্য করতে পারে। NLP ব্যবহার করে, অগ্রাধিকার টিকিট সঠিক বিভাগে পাঠানো যেতে পারে। এটি উল্লেখযোগ্যভাবে রেজোলিউশন, প্রক্রিয়াকরণ এবং পরিষেবার গতি উন্নত করে।
অবজেক্ট রিকগনিশন
স্বয়ংক্রিয় নথির শ্রেণিবিন্যাস বিভাগ অনুসারে শ্রেণীবদ্ধ করে নথিতে প্রচুর পরিমাণে ভিজ্যুয়াল ডেটা প্রক্রিয়া করতেও ব্যবহৃত হয়। বস্তুর স্বীকৃতি সাধারণত ইকমার্স বা উৎপাদন ইউনিটে পণ্য শ্রেণীবদ্ধ করতে ব্যবহৃত হয়।
এআই দ্বারা চালিত ডকুমেন্ট ক্লাসিফিকেশন দিয়ে শুরু করা
নথিতে ব্যবসার কার্যকারিতার জন্য গুরুত্বপূর্ণ ডেটা রয়েছে। নথিতে মূল্যবান অন্তর্দৃষ্টি রয়েছে যা একটি সংস্থার ক্রিয়াকলাপ, পরিষেবা এবং বৃদ্ধির লক্ষ্যগুলিকে আরও এগিয়ে নিয়ে যায়৷
যাইহোক, নথি শ্রেণীবদ্ধ করা একটি ক্লান্তিকর কিন্তু প্রয়োজনীয় কাজ। যেহেতু নথির শ্রেণিবিন্যাস একটি চ্যালেঞ্জ, বিশেষ করে যদি ভলিউম তুলনামূলকভাবে বেশি হয়, তাহলে একটি স্বয়ংক্রিয় নথি শ্রেণিবিন্যাস ব্যবস্থা থাকা প্রয়োজন।
মেশিন লার্নিং অ্যালগরিদম দ্বারা প্রশিক্ষিত একটি AI-ভিত্তিক নথি শ্রেণীবিভাগ মডেল দক্ষ, সাশ্রয়ী, ত্রুটি-মুক্ত এবং সঠিক। কিন্তু প্রক্রিয়াটি তখনই শুরু হতে পারে যখন আপনি যে মডেলটি তৈরি করছেন সেটি মানসম্পন্ন এবং সঠিকভাবে ট্যাগ করা ডেটাসেট সম্পর্কে প্রশিক্ষিত।
শাপ আপনার কাছে নিয়ে আসে প্রাক-ট্যাগ করা ডেটাসেট যেটি সঠিক শ্রেণীবিভাগ মডেল তৈরিতে সহায়তা করে। আমাদের সাথে যোগাযোগ করুন এবং এখনই আপনার নথি শ্রেণীবিভাগের টুল দিয়ে শুরু করুন।


