
অটোমেটিক স্পিচ রিকগনিশন (ASR) অনেক দূর এগিয়েছে। যদিও এটি অনেক আগে উদ্ভাবিত হয়েছিল, এটি খুব কমই কেউ ব্যবহার করেছিল। যাইহোক, সময় এবং প্রযুক্তি এখন উল্লেখযোগ্যভাবে পরিবর্তিত হয়েছে। অডিও ট্রান্সক্রিপশন উল্লেখযোগ্যভাবে বিকশিত হয়েছে।
AI (কৃত্রিম বুদ্ধিমত্তা) এর মতো প্রযুক্তিগুলি দ্রুত এবং নির্ভুল ফলাফলের জন্য অডিও-টু-টেক্সট অনুবাদের প্রক্রিয়াকে শক্তিশালী করেছে। ফলস্বরূপ, টিক টোক, স্পটিফাই এবং জুমের মতো কিছু জনপ্রিয় অ্যাপ তাদের মোবাইল অ্যাপে এই প্রক্রিয়াটিকে এমবেড করার সাথে বাস্তব জগতে এর অ্যাপ্লিকেশনগুলিও বৃদ্ধি পেয়েছে।
তাই আসুন আমরা ASR অন্বেষণ করি এবং আবিষ্কার করি কেন এটি 2022 সালের সবচেয়ে জনপ্রিয় প্রযুক্তিগুলির মধ্যে একটি।
টেক্সট থেকে বক্তৃতা কি?
স্পিচ টু টেক্সট হল একটি এআই-বর্ধিত প্রযুক্তি যা মানুষের বক্তৃতাকে এনালগ থেকে ডিজিটাল ফর্মে অনুবাদ করে। আরও, সংগৃহীত ডেটার ডিজিটাল ফর্মটি একটি পাঠ্য বিন্যাসে প্রতিলিপি করা হয়।
স্পিচ টু টেক্সট প্রায়ই ভয়েস রিকগনিশনের সাথে বিভ্রান্ত হয় যা এই পদ্ধতি থেকে সম্পূর্ণ আলাদা। ভয়েস রিকগনিশনে, মানুষের ভয়েস প্যাটার্ন সনাক্ত করার উপর ফোকাস করা হয়, যেখানে এই পদ্ধতিতে, সিস্টেমটি উচ্চারিত শব্দগুলি সনাক্ত করার চেষ্টা করে।
স্পীচ টু টেক্সটের সাধারণ নাম
এই উন্নত বক্তৃতা শনাক্তকরণ প্রযুক্তি জনপ্রিয় এবং নাম দ্বারা উল্লেখ করা হয়েছে:
- স্বয়ংক্রিয় স্পিচ রিকগনিশন (ASR)
- কন্ঠ সনান্তকরণ
- কম্পিউটার স্পিচ স্বীকৃতি
- অডিও ট্রান্সক্রিপশন
- স্ক্রিন রিডিং
স্বয়ংক্রিয় বক্তৃতা স্বীকৃতির কাজ বোঝা
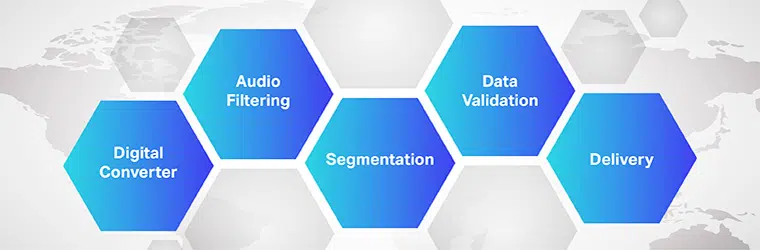
অডিও-টু-টেক্সট ট্রান্সলেশন সফ্টওয়্যারটির কাজ জটিল এবং একাধিক ধাপ বাস্তবায়ন জড়িত। আমরা জানি, স্পিচ-টু-টেক্সট হল একটি এক্সক্লুসিভ সফ্টওয়্যার যা অডিও ফাইলগুলিকে সম্পাদনাযোগ্য পাঠ্য বিন্যাসে রূপান্তর করার জন্য ডিজাইন করা হয়েছে; এটি ভয়েস স্বীকৃতি লাভের মাধ্যমে এটি করে।
প্রক্রিয়া
- প্রাথমিকভাবে, একটি এনালগ-টু-ডিজিটাল রূপান্তরকারী ব্যবহার করে, একটি কম্পিউটার প্রোগ্রাম শ্রবণ সংকেত থেকে কম্পনকে আলাদা করতে প্রদত্ত ডেটাতে ভাষাগত অ্যালগরিদম প্রয়োগ করে।
- এর পরে, শব্দ তরঙ্গ পরিমাপ করে প্রাসঙ্গিক শব্দগুলি ফিল্টার করা হয়।
- আরও, ধ্বনিগুলি সেকেন্ডের শততম বা সহস্রাংশে বিভক্ত/বিভাগ করা হয় এবং ধ্বনিগুলির সাথে মিলে যায় (একটি শব্দ থেকে অন্য শব্দকে আলাদা করার জন্য শব্দের একটি পরিমাপযোগ্য একক)।
- সুপরিচিত শব্দ, বাক্য এবং বাক্যাংশের সাথে বিদ্যমান ডেটা তুলনা করার জন্য ফোনেমগুলি আরও একটি গাণিতিক মডেলের মাধ্যমে চালিত হয়।
- আউটপুট একটি পাঠ্য বা কম্পিউটার-ভিত্তিক অডিও ফাইলে থাকে।
[এছাড়াও পড়ুন: স্বয়ংক্রিয় বক্তৃতা স্বীকৃতির একটি ব্যাপক ওভারভিউ]

স্পিচ টু টেক্সট এর ব্যবহার কি?
একাধিক স্বয়ংক্রিয় বক্তৃতা শনাক্তকরণ সফ্টওয়্যার ব্যবহার করা হয়, যেমন
- বিষয়বস্তু অনুসন্ধান: আমাদের বেশিরভাগই আমাদের ফোনে অক্ষর টাইপ করা থেকে সফ্টওয়্যারটি আমাদের ভয়েস চিনতে এবং পছন্দসই ফলাফল দেওয়ার জন্য একটি বোতাম টিপতে চলে গেছে।
- গ্রাহক সেবা: চ্যাটবট এবং এআই সহকারী যা গ্রাহকদের প্রক্রিয়ার কয়েকটি প্রাথমিক ধাপের মাধ্যমে গাইড করতে পারে তা সাধারণ হয়ে উঠেছে।
- রিয়েল-টাইম ক্লোজড ক্যাপশনিং: বিষয়বস্তুতে বিশ্বব্যাপী প্রবেশাধিকার বৃদ্ধির সাথে সাথে, রিয়েল-টাইমে ক্লোজড ক্যাপশনিং একটি বিশিষ্ট এবং উল্লেখযোগ্য বাজারে পরিণত হয়েছে, এটির ব্যবহারের জন্য ASRকে এগিয়ে নিয়ে যাচ্ছে।
- ইলেকট্রনিক ডকুমেন্টেশন: বেশ কিছু প্রশাসনিক বিভাগ এএসআর ব্যবহার শুরু করেছে ডকুমেন্টেশনের উদ্দেশ্য পূরণ করতে, আরও ভালো গতি এবং দক্ষতার জন্য।
বক্তৃতা স্বীকৃতির মূল চ্যালেঞ্জগুলি কী কী?
অডিও টীকা এখনও তার বিকাশের শিখরে পৌঁছেনি। এখনও অনেক চ্যালেঞ্জ রয়েছে যা প্রকৌশলীরা সিস্টেমটিকে দক্ষ করার জন্য মোকাবেলা করার চেষ্টা করছেন, যেমন
- উচ্চারণ এবং উপভাষার উপর নিয়ন্ত্রণ অর্জন।
- কথ্য বাক্যগুলির প্রেক্ষাপট বোঝা।
- ইনপুট গুণমান বৃদ্ধি করার জন্য পটভূমির শব্দের বিচ্ছেদ।
- দক্ষ প্রক্রিয়াকরণের জন্য কোডটি বিভিন্ন ভাষায় স্যুইচ করা।
- ভিডিও ফাইলের ক্ষেত্রে বক্তৃতায় ব্যবহৃত চাক্ষুষ সংকেত বিশ্লেষণ করা।
অডিও ট্রান্সক্রিপশন এবং স্পিচ-টু-টেক্সট এআই ডেভেলপমেন্ট
স্বয়ংক্রিয় স্পিচ রিকগনিশন সফ্টওয়্যারের সাথে সবচেয়ে বড় চ্যালেঞ্জ হল এর আউটপুট 100% নির্ভুলভাবে তৈরি করা। যেহেতু কাঁচা ডেটা গতিশীল এবং একটি একক অ্যালগরিদম প্রয়োগ করা যায় না, তাই সঠিক প্রেক্ষাপটে এটি বোঝার জন্য AI-কে প্রশিক্ষণ দেওয়ার জন্য ডেটা টীকা করা হয়।
এই প্রক্রিয়াটি সম্পাদন করার জন্য, নির্দিষ্ট কাজগুলি বাস্তবায়ন করতে হবে, যেমন:
 নামকৃত সত্তা স্বীকৃতি (NER): নেরের বিভিন্ন নামকৃত সত্ত্বাকে নির্দিষ্ট শ্রেণীতে চিহ্নিত করার এবং সেগমেন্ট করার প্রক্রিয়া।
নামকৃত সত্তা স্বীকৃতি (NER): নেরের বিভিন্ন নামকৃত সত্ত্বাকে নির্দিষ্ট শ্রেণীতে চিহ্নিত করার এবং সেগমেন্ট করার প্রক্রিয়া।- অনুভূতি এবং বিষয় বিশ্লেষণ: একাধিক অ্যালগরিদম ব্যবহার করে সফ্টওয়্যার ত্রুটি-মুক্ত ফলাফল প্রদানের জন্য প্রদত্ত ডেটার অনুভূতি বিশ্লেষণ করে।
 নামকৃত সত্তা স্বীকৃতি (NER):
নামকৃত সত্তা স্বীকৃতি (NER): - উদ্দেশ্য এবং কথোপকথন বিশ্লেষণ: অভিপ্রায় সনাক্তকরণের লক্ষ্য হল স্পিকারের উদ্দেশ্য চিনতে এআইকে প্রশিক্ষণ দেওয়া। এটি মূলত এআই-চালিত চ্যাটবট তৈরির জন্য ব্যবহৃত হয়।
উপসংহার
স্পিচ-টু-টেক্সট প্রযুক্তি এই মুহুর্তে একটি দুর্দান্ত পর্যায়ে রয়েছে। আরও ডিজিটাল ডিভাইসগুলি তাদের অ্যাপগুলিতে ভয়েস অনুসন্ধান এবং নিয়ন্ত্রণ সহকারীকে অন্তর্ভুক্ত করে, অডিও ট্রান্সক্রিপশনের চাহিদা বাড়তে চলেছে৷ আপনি যদি আপনার অ্যাপে এই চিত্তাকর্ষক বৈশিষ্ট্যটি যুক্ত করতে আগ্রহী হন তবে সম্পূর্ণ বিশদ জানতে Shaip এর বক্তৃতা ডেটা সংগ্রহ বিশেষজ্ঞদের সাথে যোগাযোগ করুন।


