
ChatGPT রাতারাতি সাফল্য লাভ করার পর বৃহৎ ভাষার মডেলগুলি সম্প্রতি ব্যাপক প্রাধান্য পেয়েছে। চ্যাটজিপিটি এবং অন্যান্য চ্যাটবট-এর সাফল্য দেখে, অনেক লোক এবং সংস্থা এই ধরনের সফ্টওয়্যারকে ক্ষমতা দেয় এমন প্রযুক্তি অন্বেষণে আগ্রহী হয়ে উঠেছে।
বড় ভাষা মডেলগুলি এই সফ্টওয়্যারটির পিছনে মেরুদণ্ড যা মেশিন অনুবাদ, বক্তৃতা স্বীকৃতি, প্রশ্নের উত্তর এবং পাঠ্য সংক্ষিপ্তকরণের মতো বিভিন্ন প্রাকৃতিক ভাষা প্রক্রিয়াকরণ অ্যাপ্লিকেশনগুলির কাজকে সক্ষম করে। আসুন আমরা এলএলএম সম্পর্কে আরও শিখি এবং কীভাবে আপনি সেরা ফলাফলের জন্য এটি অপ্টিমাইজ করতে পারেন।
বড় ভাষা মডেল বা ChatGPT কি?
বড় ভাষা মডেলগুলি হল মেশিন লার্নিং মডেল যা কৃত্রিম নিউরাল নেটওয়ার্ক এবং এনএলপি অ্যাপ্লিকেশনগুলিকে পাওয়ার জন্য ডেটার বড় সাইলো ব্যবহার করে। প্রচুর পরিমাণে ডেটার উপর প্রশিক্ষণের পরে, এলএলএম প্রাকৃতিক ভাষার বিভিন্ন জটিলতাগুলি ক্যাপচার করার ক্ষমতা অর্জন করে, যা এটি আরও ব্যবহার করে:
- নতুন পাঠ্যের প্রজন্ম
- নিবন্ধ এবং প্যাসেজের সারসংক্ষেপ
- তথ্য নিষ্কাশন
- টেক্সট পুনর্লিখন বা প্যারাফ্রেজিং
- তথ্য শ্রেণীবদ্ধ
LLM-এর কিছু জনপ্রিয় উদাহরণ হল BERT, Chat GPT-3, এবং XLNet। এই মডেলগুলি লক্ষ লক্ষ পাঠ্যের উপর প্রশিক্ষিত এবং সমস্ত ধরণের স্বতন্ত্র ব্যবহারকারীর প্রশ্নের সার্থক সমাধান প্রদান করতে পারে৷
বড় ভাষার মডেলের জনপ্রিয় ব্যবহারের ক্ষেত্রে
এখানে এলএলএম-এর কিছু শীর্ষ এবং সর্বাধিক প্রচলিত ব্যবহারের ক্ষেত্রে রয়েছে:
টেক্সট জেনারেশন
বড় ভাষার মডেলগুলি স্বয়ংক্রিয়ভাবে প্রাকৃতিক ভাষার পাঠ্য তৈরি করতে এবং নিবন্ধ, গান লেখা বা এমনকি ব্যবহারকারীদের সাথে চ্যাট করার মতো বিভিন্ন যোগাযোগমূলক ব্যবহারকারীর প্রয়োজনীয়তা পূরণ করতে কৃত্রিম বুদ্ধিমত্তা এবং গণনামূলক ভাষাবিজ্ঞানের জ্ঞান ব্যবহার করে।
যন্ত্রানুবাদ
এলএলএমগুলি যে কোনও দুটি ভাষার মধ্যে পাঠ্য অনুবাদ করতেও ব্যবহার করা যেতে পারে। মডেলগুলি গভীর শিক্ষার অ্যালগরিদমগুলি ব্যবহার করে, যেমন পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলি, উৎসের ভাষা গঠন এবং লক্ষ্য ভাষা শিখতে। তদনুসারে, তারা টার্গেট ভাষায় উত্স পাঠ্য অনুবাদের জন্য ব্যবহৃত হয়।
বিষয়বস্তু নির্মাণ
এলএলএমগুলি এখন মেশিনগুলির পক্ষে সুসংগত এবং যৌক্তিক সামগ্রী তৈরি করা সম্ভব করেছে যা ব্লগ পোস্ট, নিবন্ধ এবং অন্যান্য ধরণের সামগ্রী তৈরি করতে ব্যবহার করা যেতে পারে। মডেলগুলি ব্যবহারকারীদের জন্য একটি অনন্য এবং পাঠযোগ্য বিন্যাসে বিষয়বস্তু বুঝতে এবং গঠন করতে তাদের বিস্তৃত গভীর-শিক্ষার জ্ঞান ব্যবহার করে।
অনুভূতির বিশ্লেষণ
এটি বৃহৎ ভাষার মডেলগুলির একটি উত্তেজনাপূর্ণ ব্যবহারের ক্ষেত্রে যেখানে মডেলটিকে লেবেলযুক্ত পাঠ্যে সংবেদনশীল অবস্থা এবং অনুভূতিগুলি সনাক্ত এবং শ্রেণিবদ্ধ করার জন্য প্রশিক্ষণ দেওয়া হয়। সফ্টওয়্যারটি ইতিবাচকতা, নেতিবাচকতা, নিরপেক্ষতা এবং অন্যান্য জটিল অনুভূতির মতো আবেগগুলি সনাক্ত করতে পারে যা গ্রাহকদের মতামত এবং বিভিন্ন পণ্য এবং পরিষেবা সম্পর্কে পর্যালোচনাগুলির অন্তর্দৃষ্টি পেতে সাহায্য করতে পারে৷
অনুধাবন, সংক্ষিপ্তকরণ, এবং পাঠ্যের শ্রেণীবিভাগ
এলএলএম এআই সফ্টওয়্যার পাঠ্য এবং এর প্রসঙ্গ বোঝার জন্য একটি ব্যবহারিক কাঠামো প্রদান করে। মডেলটিকে প্রচুর পরিমাণে ডেটা বোঝার এবং বিশ্লেষণ করার প্রশিক্ষণ দিয়ে, এলএলএম এআই মডেলগুলিকে বিভিন্ন ফর্ম এবং প্যাটার্নে পাঠ্যকে বোঝা, সংক্ষিপ্তকরণ এবং এমনকি শ্রেণিবদ্ধ করতে সক্ষম করে।
প্রশ্নের উত্তর
বৃহৎ ভাষার মডেলগুলি QA সিস্টেমগুলিকে ব্যবহারকারীর স্বাভাবিক ভাষা প্রশ্নের সঠিকভাবে সনাক্ত করতে এবং উত্তর দিতে সক্ষম করে৷ এই ব্যবহারের ক্ষেত্রে সবচেয়ে জনপ্রিয় অ্যাপ্লিকেশনগুলির মধ্যে একটি হল ChatGPT এবং BERT, যেটি একটি প্রশ্নের প্রেক্ষাপট বিশ্লেষণ করে এবং ব্যবহারকারীর প্রশ্নের প্রাসঙ্গিক উত্তর খুঁজে পেতে পাঠ্যের একটি বড় অংশের মাধ্যমে অনুসন্ধান করে।
[এছাড়াও পড়ুন: ভাষা প্রক্রিয়াকরণের ভবিষ্যৎ: বড় ভাষা মডেল এবং উদাহরণ ]

LLM সফল করার জন্য 3টি অপরিহার্য শর্ত
দক্ষতা বাড়াতে এবং আপনার বড় ভাষার মডেলগুলিকে সফল করতে নিম্নলিখিত তিনটি শর্ত অবশ্যই সঠিকভাবে পূরণ করতে হবে:
মডেল প্রশিক্ষণের জন্য বিপুল পরিমাণ ডেটার উপস্থিতি
দক্ষ এবং সর্বোত্তম ফলাফল প্রদান করে এমন মডেলগুলিকে প্রশিক্ষণের জন্য LLM-এর প্রচুর পরিমাণে ডেটা প্রয়োজন। ট্রান্সফার লার্নিং এবং স্ব-তত্ত্বাবধানে প্রাক-প্রশিক্ষণের মতো নির্দিষ্ট পদ্ধতি রয়েছে, যা এলএলএম তাদের কর্মক্ষমতা এবং নির্ভুলতা উন্নত করতে ব্যবহার করে।
মডেলগুলির জটিল প্যাটার্নগুলি সহজতর করার জন্য নিউরনের স্তরগুলি তৈরি করা৷
একটি বৃহৎ ভাষার মডেলে নিউরনের বিভিন্ন স্তর থাকতে হবে যা ডেটার জটিল নিদর্শন বোঝার জন্য বিশেষভাবে প্রশিক্ষিত। গভীর স্তরের নিউরনগুলি অগভীর স্তরগুলির চেয়ে জটিল নিদর্শনগুলি আরও ভালভাবে বুঝতে পারে। মডেলটি শব্দের মধ্যে সংযোগ, বিষয়গুলি যেগুলি একসাথে প্রদর্শিত হয় এবং বক্তৃতার অংশগুলির মধ্যে সম্পর্ক শিখতে পারে।
ব্যবহারকারী-নির্দিষ্ট কাজের জন্য LLM-এর অপ্টিমাইজেশন
স্তর, নিউরন এবং অ্যাক্টিভেশন ফাংশনগুলির সংখ্যা পরিবর্তন করে নির্দিষ্ট কাজের জন্য এলএলএমগুলিকে টুইক করা যেতে পারে। উদাহরণস্বরূপ, একটি মডেল যা বাক্যে নিম্নলিখিত শব্দের পূর্বাভাস দেয় সাধারণত স্ক্র্যাচ থেকে নতুন বাক্য তৈরি করার জন্য ডিজাইন করা মডেলের তুলনায় কম স্তর এবং নিউরন ব্যবহার করে।
বড় ভাষার মডেলের জনপ্রিয় উদাহরণ
এখানে বিভিন্ন শিল্প উল্লম্বে ব্যাপকভাবে ব্যবহৃত এলএলএম-এর কয়েকটি বিশিষ্ট উদাহরণ রয়েছে:
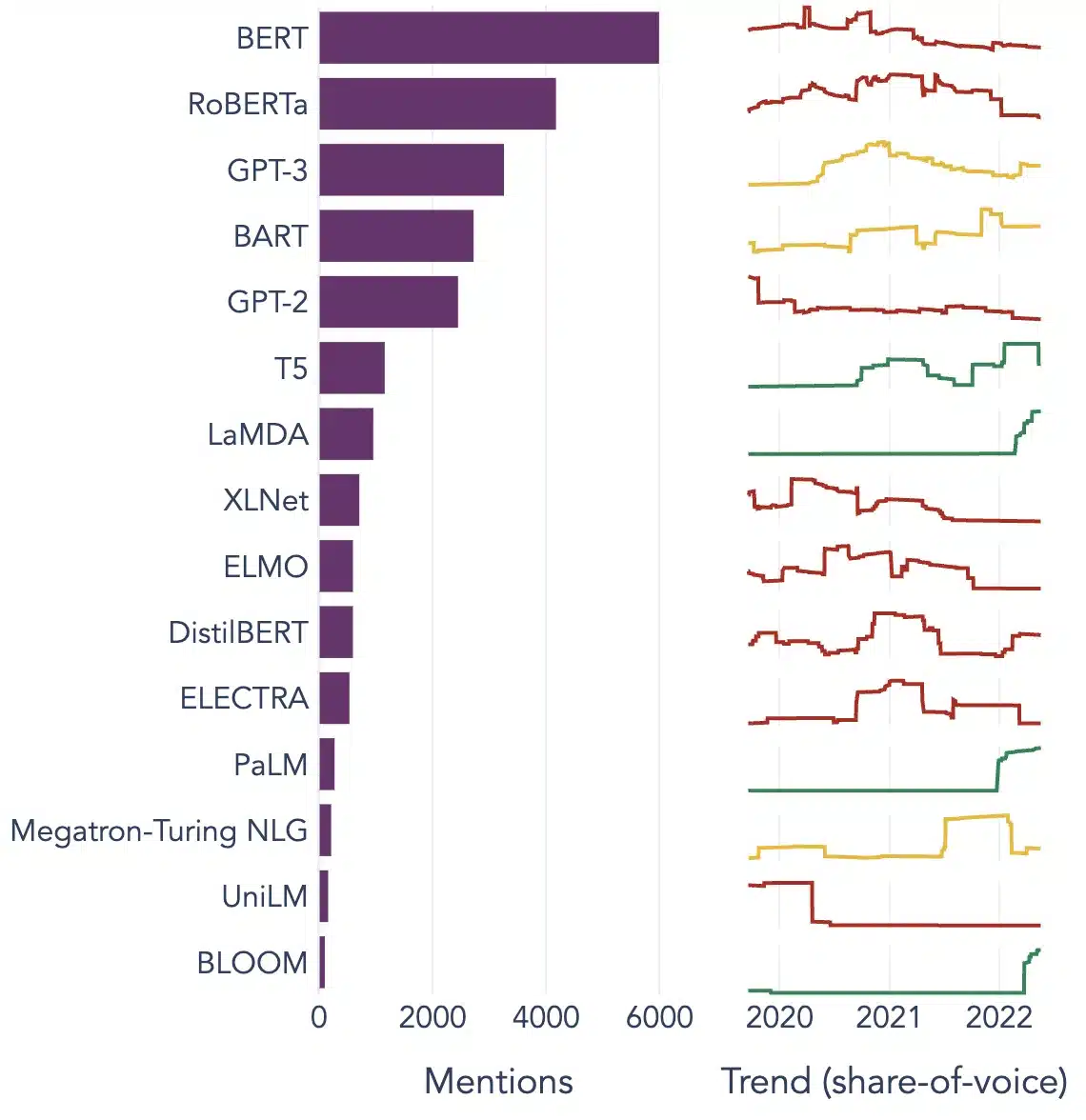
চিত্র উত্স: তথ্য বিজ্ঞানের দিকে
উপসংহার
এলএলএমগুলি শক্তিশালী এবং নির্ভুল ভাষা বোঝার ক্ষমতা এবং সমাধান প্রদান করে যা একটি বিরামহীন ব্যবহারকারীর অভিজ্ঞতা প্রদান করে এনএলপিতে বিপ্লব করার সম্ভাবনা দেখে। যাইহোক, এলএলএমগুলিকে আরও দক্ষ করে তুলতে, আরও সঠিক ফলাফল তৈরি করতে এবং অত্যন্ত কার্যকর AI মডেল তৈরি করতে বিকাশকারীদের অবশ্যই উচ্চ-মানের স্পিচ ডেটা ব্যবহার করতে হবে।
Shaip হল একটি নেতৃস্থানীয় AI প্রযুক্তি সমাধান যা 50 টিরও বেশি ভাষা এবং একাধিক ফর্ম্যাটে বিস্তৃত স্পিচ ডেটা অফার করে৷ এলএলএম সম্পর্কে আরও জানুন এবং আপনার প্রকল্পগুলির বিষয়ে নির্দেশিকা নিন শাইপ বিশেষজ্ঞরা আজ.


