

বড় ভাষা মডেল কি?
লার্জ ল্যাঙ্গুয়েজ মডেল (LLMs) হল উন্নত কৃত্রিম বুদ্ধিমত্তা (AI) সিস্টেম যা মানুষের মতো পাঠ্য প্রক্রিয়া, বোঝা এবং তৈরি করার জন্য ডিজাইন করা হয়েছে। এগুলি গভীর শিক্ষার কৌশলগুলির উপর ভিত্তি করে এবং বিশাল ডেটাসেটের উপর প্রশিক্ষিত, সাধারণত ওয়েবসাইট, বই এবং নিবন্ধগুলির মতো বিভিন্ন উত্স থেকে কোটি কোটি শব্দ থাকে৷ এই ব্যাপক প্রশিক্ষণ এলএলএমদের ভাষা, ব্যাকরণ, প্রসঙ্গ এবং এমনকি সাধারণ জ্ঞানের কিছু দিক বুঝতে সক্ষম করে।
কিছু জনপ্রিয় এলএলএম, যেমন OpenAI-এর GPT-3, ট্রান্সফরমার নামে এক ধরনের নিউরাল নেটওয়ার্ক নিয়োগ করে, যা তাদের অসাধারণ দক্ষতার সাথে জটিল ভাষার কাজগুলি পরিচালনা করতে দেয়। এই মডেলগুলি বিস্তৃত কাজ সম্পাদন করতে পারে, যেমন:
- প্রশ্নের উত্তর দিচ্ছি
- টেক্সট সারসংক্ষেপ
- ভাষাগুলি অনুবাদ করা
- সামগ্রী তৈরি করা হচ্ছে
- এমনকি ব্যবহারকারীদের সাথে ইন্টারেক্টিভ কথোপকথনে জড়িত
যেহেতু এলএলএমগুলি বিকশিত হতে থাকে, তারা গ্রাহক পরিষেবা এবং বিষয়বস্তু তৈরি থেকে শুরু করে শিক্ষা এবং গবেষণা পর্যন্ত শিল্প জুড়ে বিভিন্ন অ্যাপ্লিকেশনগুলিকে উন্নত এবং স্বয়ংক্রিয় করার জন্য প্রচুর সম্ভাবনা রাখে। যাইহোক, তারা নৈতিক এবং সামাজিক উদ্বেগও উত্থাপন করে, যেমন পক্ষপাতদুষ্ট আচরণ বা অপব্যবহার, যা প্রযুক্তির অগ্রগতি হিসাবে সমাধান করা প্রয়োজন।

বড় ভাষার মডেলের জনপ্রিয় উদাহরণ
এখানে বিভিন্ন শিল্প উল্লম্বে ব্যাপকভাবে ব্যবহৃত এলএলএম-এর কয়েকটি বিশিষ্ট উদাহরণ রয়েছে:
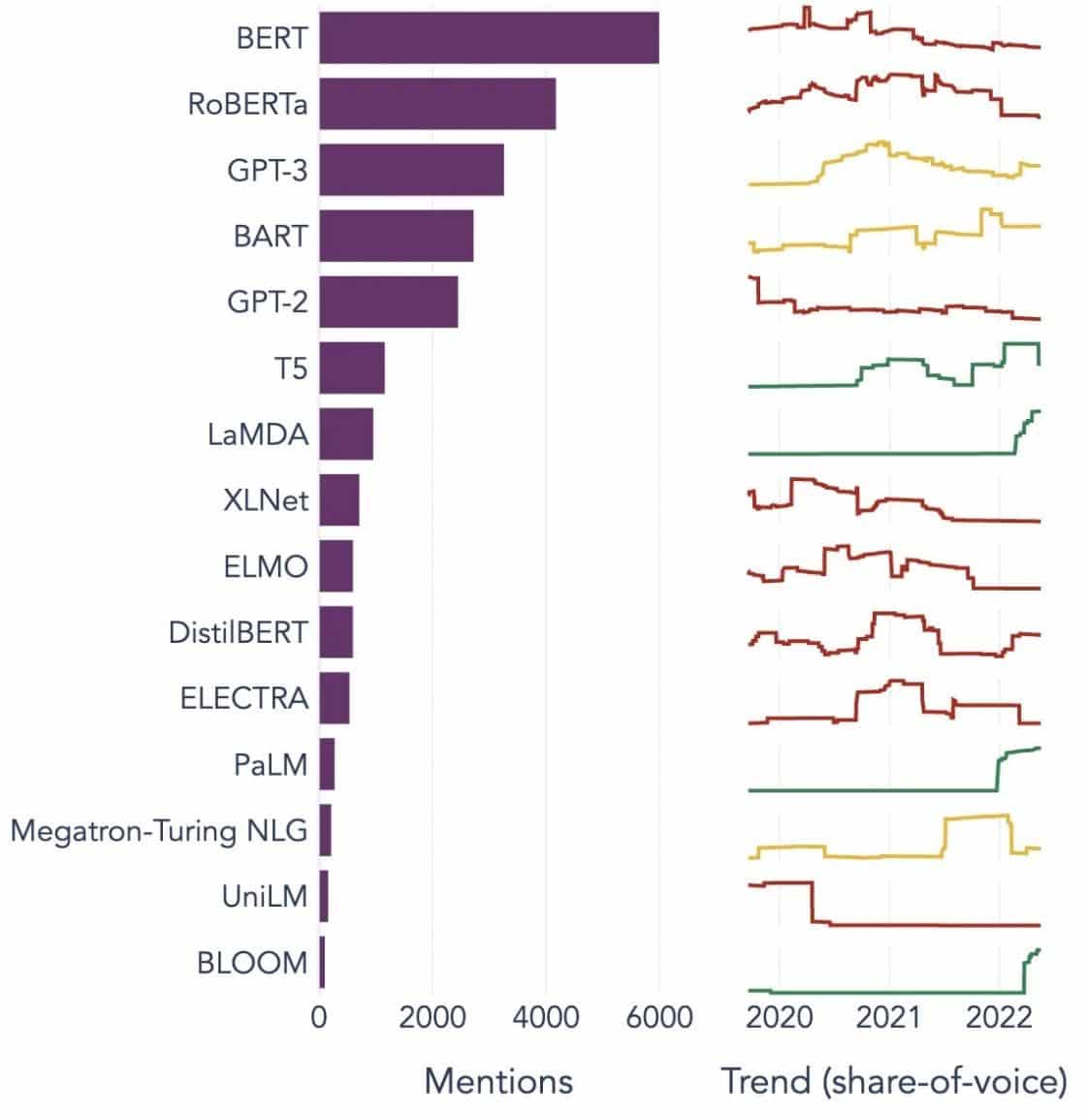
চিত্র উত্স: তথ্য বিজ্ঞানের দিকে
এলএলএম মডেলগুলি কীভাবে প্রশিক্ষিত হয়?
বৃহৎ ভাষা মডেল (এলএলএম) প্রশিক্ষণ দেওয়া বেশ একটি কৃতিত্ব যা বেশ কয়েকটি গুরুত্বপূর্ণ পদক্ষেপ জড়িত। এখানে প্রক্রিয়াটির একটি সরলীকৃত, ধাপে ধাপে রানডাউন রয়েছে:
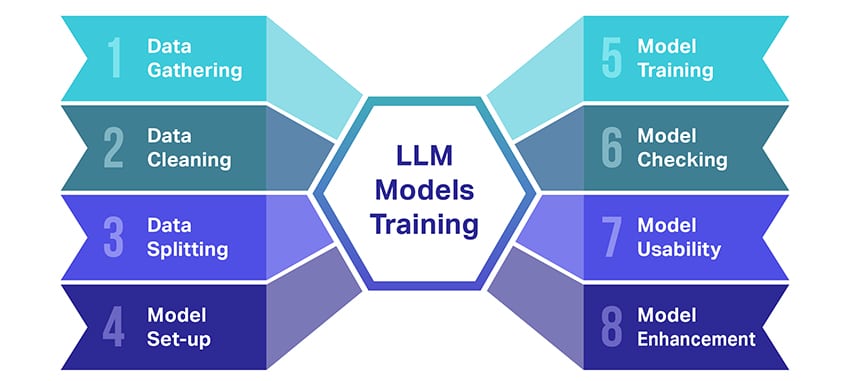
- পাঠ্য তথ্য সংগ্রহ করা: একটি এলএলএম প্রশিক্ষণ বিপুল পরিমাণ পাঠ্য ডেটা সংগ্রহের মাধ্যমে শুরু হয়। এই ডেটা বই, ওয়েবসাইট, নিবন্ধ, বা সামাজিক মিডিয়া প্ল্যাটফর্ম থেকে আসতে পারে। উদ্দেশ্য মানুষের ভাষার সমৃদ্ধ বৈচিত্র্য ক্যাপচার করা.
- ডেটা পরিষ্কার করা: কাঁচা টেক্সট ডেটা তারপর প্রিপ্রসেসিং নামক একটি প্রক্রিয়ায় সাজানো হয়। এর মধ্যে অবাঞ্ছিত অক্ষরগুলি সরানো, টোকেন নামক ছোট অংশে পাঠ্যকে ভেঙে ফেলা এবং মডেলটি কাজ করতে পারে এমন একটি বিন্যাসে এই সমস্ত কাজগুলি অন্তর্ভুক্ত করে৷
- ডেটা বিভাজন: এর পরে, পরিষ্কার ডেটা দুটি সেটে বিভক্ত করা হয়। একটি সেট, প্রশিক্ষণ ডেটা, মডেলটি প্রশিক্ষণের জন্য ব্যবহার করা হবে। অন্য সেট, বৈধতা ডেটা, মডেলের কর্মক্ষমতা পরীক্ষা করার জন্য পরে ব্যবহার করা হবে।
- মডেল সেট আপ করা হচ্ছে: LLM এর গঠন, যা আর্কিটেকচার নামে পরিচিত, তারপর সংজ্ঞায়িত করা হয়। এতে নিউরাল নেটওয়ার্কের ধরন নির্বাচন করা এবং নেটওয়ার্কের মধ্যে স্তরের সংখ্যা এবং লুকানো ইউনিটের মতো বিভিন্ন পরামিতি সম্পর্কে সিদ্ধান্ত নেওয়া জড়িত।
- মডেল প্রশিক্ষণ: প্রকৃত প্রশিক্ষণ এখন শুরু হয়। LLM মডেল প্রশিক্ষণের ডেটা দেখে, এ পর্যন্ত যা শিখেছে তার উপর ভিত্তি করে ভবিষ্যদ্বাণী করে, এবং তারপরে এর ভবিষ্যদ্বাণী এবং প্রকৃত ডেটার মধ্যে পার্থক্য কমাতে এর অভ্যন্তরীণ প্যারামিটারগুলি সামঞ্জস্য করে।
- মডেল পরীক্ষা করা হচ্ছে: এলএলএম মডেলের শিক্ষা যাচাই করা হয় বৈধতা ডেটা ব্যবহার করে। এটি মডেলটি কতটা ভাল পারফর্ম করছে তা দেখতে এবং আরও ভাল পারফরম্যান্সের জন্য মডেলের সেটিংস পরিবর্তন করতে সহায়তা করে।
- মডেল ব্যবহার করে: প্রশিক্ষণ এবং মূল্যায়নের পর, এলএলএম মডেলটি ব্যবহারের জন্য প্রস্তুত। এটি এখন অ্যাপ্লিকেশন বা সিস্টেমে একত্রিত করা যেতে পারে যেখানে এটি দেওয়া নতুন ইনপুটগুলির উপর ভিত্তি করে পাঠ্য তৈরি করবে।
- মডেল উন্নত করা: অবশেষে, উন্নতির জন্য সবসময় জায়গা আছে। LLM মডেলটিকে সময়ের সাথে সাথে আরও পরিমার্জিত করা যেতে পারে, আপডেট করা ডেটা ব্যবহার করে বা প্রতিক্রিয়া এবং বাস্তব-বিশ্ব ব্যবহারের উপর ভিত্তি করে সেটিংস সামঞ্জস্য করে।
মনে রাখবেন, এই প্রক্রিয়াটির জন্য গুরুত্বপূর্ণ গণনামূলক সংস্থান প্রয়োজন, যেমন শক্তিশালী প্রক্রিয়াকরণ ইউনিট এবং বড় স্টোরেজ, সেইসাথে মেশিন লার্নিংয়ে বিশেষ জ্ঞান। এজন্য এটি সাধারণত প্রয়োজনীয় অবকাঠামো এবং দক্ষতার অ্যাক্সেস সহ উত্সর্গীকৃত গবেষণা সংস্থা বা সংস্থাগুলি দ্বারা করা হয়।
এলএলএম কি তত্ত্বাবধানে বা অনিয়ন্ত্রিত শিক্ষার উপর নির্ভর করে?
বৃহৎ ভাষার মডেলগুলিকে সাধারণত তত্ত্বাবধানে শেখার পদ্ধতি ব্যবহার করে প্রশিক্ষণ দেওয়া হয়। সহজ কথায়, এর অর্থ হল তারা এমন উদাহরণ থেকে শিখে যা তাদের সঠিক উত্তর দেখায়।
 কল্পনা করুন আপনি একটি শিশুকে ছবি দেখিয়ে শব্দ শেখাচ্ছেন। আপনি তাদের একটি বিড়ালের একটি ছবি দেখান এবং "বিড়াল" বলুন এবং তারা সেই ছবিটিকে শব্দের সাথে যুক্ত করতে শিখবে। এভাবেই তত্ত্বাবধানে শেখা কাজ করে। মডেলটিকে প্রচুর পাঠ্য ("ছবি") এবং সংশ্লিষ্ট আউটপুট ("শব্দ") দেওয়া হয় এবং এটি তাদের সাথে মিলিত হতে শেখে।
কল্পনা করুন আপনি একটি শিশুকে ছবি দেখিয়ে শব্দ শেখাচ্ছেন। আপনি তাদের একটি বিড়ালের একটি ছবি দেখান এবং "বিড়াল" বলুন এবং তারা সেই ছবিটিকে শব্দের সাথে যুক্ত করতে শিখবে। এভাবেই তত্ত্বাবধানে শেখা কাজ করে। মডেলটিকে প্রচুর পাঠ্য ("ছবি") এবং সংশ্লিষ্ট আউটপুট ("শব্দ") দেওয়া হয় এবং এটি তাদের সাথে মিলিত হতে শেখে।
সুতরাং, যদি আপনি একটি LLM একটি বাক্য খাওয়ান, এটি উদাহরণ থেকে যা শিখেছে তার উপর ভিত্তি করে পরবর্তী শব্দ বা বাক্যাংশটি ভবিষ্যদ্বাণী করার চেষ্টা করে। এইভাবে, এটি কীভাবে পাঠ্য তৈরি করতে হয় তা শিখে যায় যা বোঝায় এবং প্রসঙ্গের সাথে খাপ খায়।
এটি বলেছে, কখনও কখনও এলএলএমগুলিও কিছুটা তত্ত্বাবধানহীন শিক্ষা ব্যবহার করে। এটি শিশুকে বিভিন্ন খেলনা দিয়ে ভরা একটি রুম অন্বেষণ করার এবং সেগুলি সম্পর্কে নিজে থেকে শিখতে দেওয়ার মতো। মডেলটি "সঠিক" উত্তর না বলেই লেবেলবিহীন ডেটা, শেখার ধরণ এবং কাঠামো দেখে।
তত্ত্বাবধানে থাকা শিক্ষা এমন ডেটা নিয়োগ করে যা ইনপুট এবং আউটপুট দিয়ে লেবেল করা হয়েছে, তত্ত্বাবধানহীন শিক্ষার বিপরীতে, যা লেবেলযুক্ত আউটপুট ডেটা ব্যবহার করে না।
সংক্ষেপে, এলএলএমগুলিকে প্রধানত তত্ত্বাবধানে শিক্ষার মাধ্যমে প্রশিক্ষিত করা হয়, তবে তারা তাদের ক্ষমতা বাড়ানোর জন্য, যেমন অন্বেষণমূলক বিশ্লেষণ এবং মাত্রা হ্রাসের জন্য তত্ত্বাবধানহীন শিক্ষা ব্যবহার করতে পারে।
একটি বড় ভাষার মডেল প্রশিক্ষণের জন্য প্রয়োজনীয় ডেটা ভলিউম (জিবি-তে) কী?
স্পিচ ডাটা রিকগনিশন এবং ভয়েস অ্যাপ্লিকেশানগুলির জন্য সম্ভাবনার জগৎ প্রচুর, এবং এগুলি অনেকগুলি অ্যাপ্লিকেশনের জন্য বিভিন্ন শিল্পে ব্যবহৃত হচ্ছে।
একটি বৃহৎ ভাষা মডেল প্রশিক্ষণ একটি এক-আকার-ফিট-সমস্ত প্রক্রিয়া নয়, বিশেষ করে যখন এটি প্রয়োজনীয় ডেটা আসে। এটি অনেকগুলি জিনিসের উপর নির্ভর করে:
- মডেল ডিজাইন।
- এটা কি কাজ করতে হবে?
- আপনি যে ধরনের ডেটা ব্যবহার করছেন।
- আপনি এটি কতটা ভাল করতে চান?
যে বলে, এলএলএম প্রশিক্ষণের জন্য সাধারণত প্রচুর পরিমাণে পাঠ্য ডেটার প্রয়োজন হয়। কিন্তু আমরা কতটা বড় কথা বলছি? ঠিক আছে, গিগাবাইট (জিবি) এর বাইরেও চিন্তা করুন। আমরা সাধারণত টেরাবাইট (টিবি) বা এমনকি পেটাবাইট (পিবি) ডেটা দেখছি।
GPT-3 বিবেচনা করুন, চারপাশের সবচেয়ে বড় এলএলএমগুলির মধ্যে একটি৷ এটির উপর প্রশিক্ষণ দেওয়া হয় 570 গিগাবাইট টেক্সট ডেটা. ছোট এলএলএম-এর কম প্রয়োজন হতে পারে - হতে পারে 10-20 জিবি বা এমনকি 1 জিবি গিগাবাইট - তবে এটি এখনও অনেক।

কিন্তু এটা শুধু তথ্যের আকার সম্পর্কে নয়। গুণমানও গুরুত্বপূর্ণ। মডেলটিকে কার্যকরভাবে শিখতে সাহায্য করার জন্য ডেটা পরিষ্কার এবং বৈচিত্র্যময় হতে হবে। এবং আপনি ধাঁধার অন্যান্য মূল অংশগুলি ভুলে যেতে পারবেন না, যেমন আপনার প্রয়োজনীয় কম্পিউটিং শক্তি, প্রশিক্ষণের জন্য আপনি যে অ্যালগরিদমগুলি ব্যবহার করেন এবং আপনার হার্ডওয়্যার সেটআপ। এই সমস্ত কারণগুলি এলএলএম প্রশিক্ষণে একটি বড় ভূমিকা পালন করে।
বড় ভাষার মডেলের উত্থান: কেন তারা গুরুত্বপূর্ণ
এলএলএম এখন আর শুধু একটি ধারণা বা পরীক্ষা নয়। তারা ক্রমবর্ধমানভাবে আমাদের ডিজিটাল ল্যান্ডস্কেপে একটি গুরুত্বপূর্ণ ভূমিকা পালন করছে। কিন্তু কেন এমন হচ্ছে? কি এই এলএলএমগুলিকে এত গুরুত্বপূর্ণ করে তোলে? চলুন কিছু মূল কারণের মধ্যে delve.
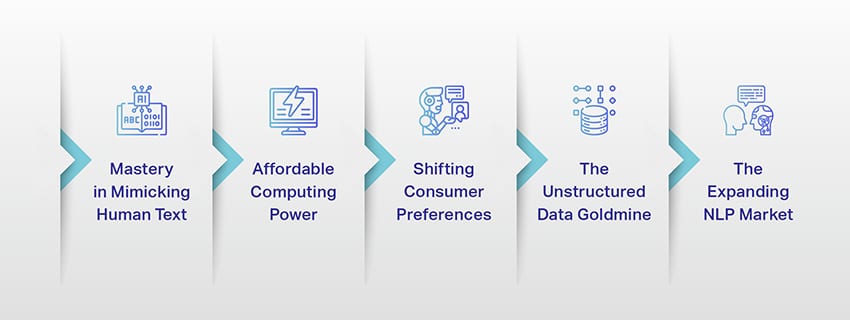
হিউম্যান টেক্সট অনুকরণে দক্ষতা
এলএলএমগুলি আমরা ভাষা-ভিত্তিক কাজগুলি পরিচালনা করার উপায়কে রূপান্তরিত করেছে। শক্তিশালী মেশিন লার্নিং অ্যালগরিদম ব্যবহার করে নির্মিত, এই মডেলগুলি কিছু পরিমাণে প্রসঙ্গ, আবেগ এবং এমনকি ব্যঙ্গ সহ মানব ভাষার সূক্ষ্মতা বোঝার ক্ষমতা দিয়ে সজ্জিত। মানুষের ভাষা অনুকরণ করার এই ক্ষমতা নিছক নতুনত্ব নয়, এর উল্লেখযোগ্য প্রভাব রয়েছে।
এলএলএম-এর উন্নত টেক্সট জেনারেশন ক্ষমতা সামগ্রী তৈরি থেকে গ্রাহক পরিষেবা মিথস্ক্রিয়া সব কিছুকে উন্নত করতে পারে।
একটি ডিজিটাল সহকারীকে একটি জটিল প্রশ্ন জিজ্ঞাসা করতে এবং এমন একটি উত্তর পাওয়ার কথা কল্পনা করুন যা কেবল অর্থবোধক নয়, বরং সুসঙ্গত, প্রাসঙ্গিক এবং কথোপকথনের সুরে সরবরাহ করাও। এটিই এলএলএমগুলি সক্ষম করছে৷ তারা আরও স্বজ্ঞাত এবং আকর্ষক মানব-মেশিন মিথস্ক্রিয়াকে উত্সাহিত করছে, ব্যবহারকারীর অভিজ্ঞতাকে সমৃদ্ধ করছে এবং তথ্যের অ্যাক্সেসকে গণতন্ত্রীকরণ করছে।
সাশ্রয়ী মূল্যের কম্পিউটিং শক্তি
কম্পিউটিং ক্ষেত্রে সমান্তরাল উন্নয়ন ছাড়া এলএলএম-এর উত্থান সম্ভব হত না। আরও নির্দিষ্টভাবে, গণনামূলক সংস্থানগুলির গণতন্ত্রীকরণ এলএলএমগুলির বিবর্তন এবং গ্রহণে একটি গুরুত্বপূর্ণ ভূমিকা পালন করেছে।
ক্লাউড-ভিত্তিক প্ল্যাটফর্মগুলি উচ্চ-পারফরম্যান্স কম্পিউটিং সংস্থানগুলিতে অভূতপূর্ব অ্যাক্সেস সরবরাহ করছে। এইভাবে, এমনকি ছোট আকারের সংস্থা এবং স্বাধীন গবেষকরাও অত্যাধুনিক মেশিন লার্নিং মডেলগুলিকে প্রশিক্ষণ দিতে পারে।
অধিকন্তু, প্রসেসিং ইউনিটের উন্নতি (যেমন GPU এবং TPUs), বিতরণকৃত কম্পিউটিং এর উত্থানের সাথে মিলিত, বিলিয়ন প্যারামিটার সহ মডেলগুলিকে প্রশিক্ষণ দেওয়া সম্ভবপর করে তুলেছে। কম্পিউটিং শক্তির এই বর্ধিত অ্যাক্সেসিবিলিটি এলএলএম-এর বৃদ্ধি এবং সাফল্যকে সক্ষম করে, যা ক্ষেত্রে আরও উদ্ভাবন এবং অ্যাপ্লিকেশনের দিকে পরিচালিত করে।
ভোক্তা পছন্দ স্থানান্তর
ভোক্তারা আজ শুধু উত্তর চান না; তারা আকর্ষণীয় এবং সম্পর্কিত মিথস্ক্রিয়া চায়। যত বেশি মানুষ ডিজিটাল প্রযুক্তি ব্যবহার করে বড় হচ্ছে, এটা স্পষ্ট যে এমন প্রযুক্তির প্রয়োজনীয়তা যা আরও প্রাকৃতিক এবং মানুষের মতো মনে হয়। মানুষের মতো পাঠ্য তৈরি করে, এই মডেলগুলি আকর্ষক এবং গতিশীল ডিজিটাল অভিজ্ঞতা তৈরি করতে পারে, যা ব্যবহারকারীর সন্তুষ্টি এবং বিশ্বস্ততা বাড়াতে পারে। গ্রাহক পরিষেবা প্রদানকারী AI চ্যাটবট হোক বা খবরের আপডেট প্রদানকারী ভয়েস সহকারী, এলএলএমগুলি এআই-এর যুগের সূচনা করছে যা আমাদের আরও ভালভাবে বোঝে।
অসংগঠিত ডেটা গোল্ডমাইন
অসংগঠিত ডেটা, যেমন ইমেল, সোশ্যাল মিডিয়া পোস্ট এবং গ্রাহক পর্যালোচনা, অন্তর্দৃষ্টির ভান্ডার। এটা আনুমানিক যে শেষ 80% এন্টারপ্রাইজ ডেটা অসংগঠিত এবং হারে বৃদ্ধি পাচ্ছে 55% প্রতি বছরে. সঠিকভাবে ব্যবহার করা হলে এই ডেটা ব্যবসার জন্য সোনার খনি।
এলএলএমগুলি এখানে কার্যকর হয়, তাদের দক্ষতার সাথে এই ধরনের ডেটা প্রসেস করার এবং স্কেলে বোঝার ক্ষমতা। তারা অনুভূতি বিশ্লেষণ, পাঠ্য শ্রেণিবিন্যাস, তথ্য নিষ্কাশন এবং আরও অনেক কিছু পরিচালনা করতে পারে, যার ফলে মূল্যবান অন্তর্দৃষ্টি প্রদান করে।
এটি সোশ্যাল মিডিয়া পোস্ট থেকে প্রবণতা সনাক্ত করা হোক বা পর্যালোচনা থেকে গ্রাহকের মনোভাব পরিমাপ করা হোক না কেন, এলএলএমগুলি ব্যবসায়গুলিকে বিশাল পরিমাণে অসংগঠিত ডেটা নেভিগেট করতে এবং ডেটা-চালিত সিদ্ধান্ত নিতে সহায়তা করছে৷
প্রসারিত এনএলপি বাজার
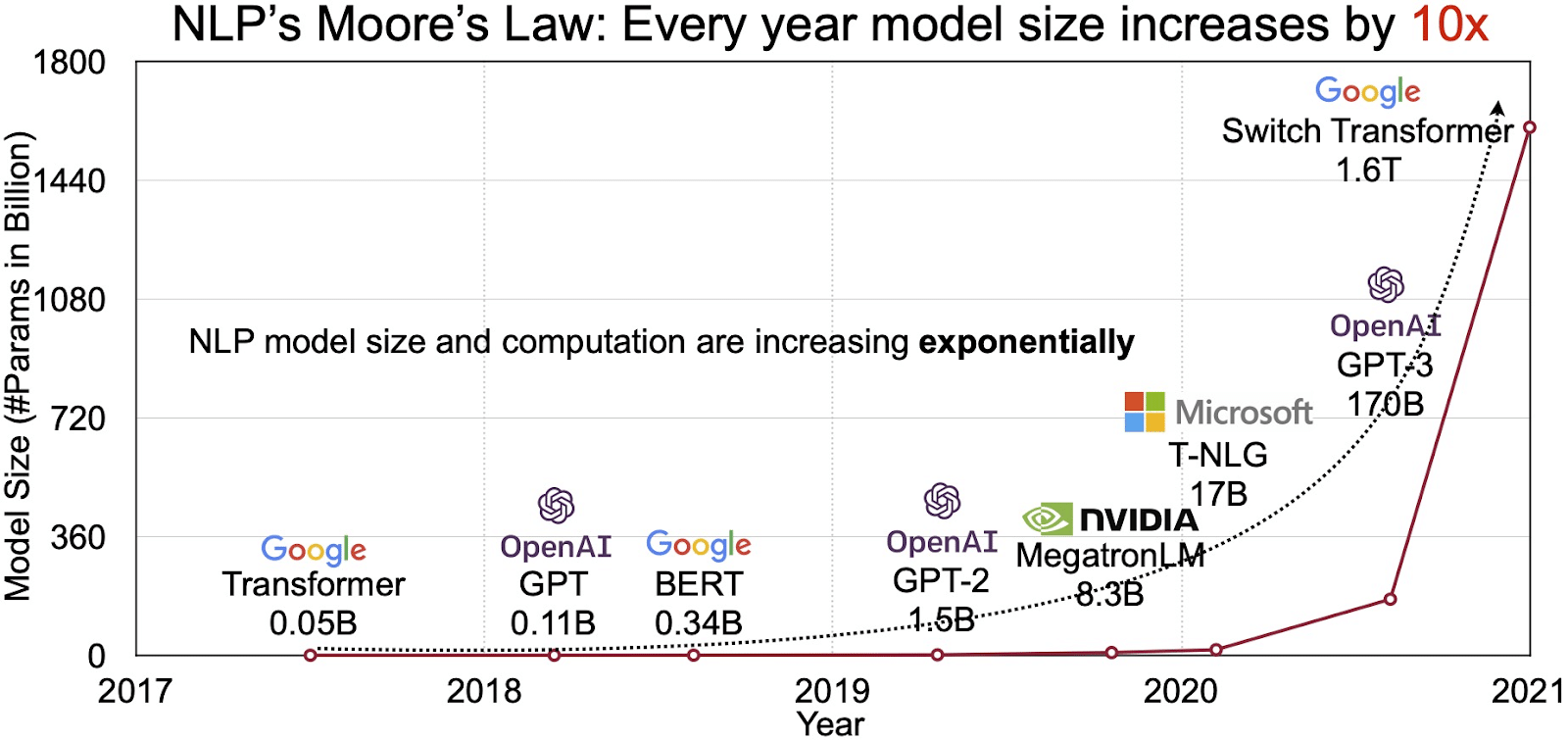
প্রাকৃতিক ভাষা প্রক্রিয়াকরণের (NLP) জন্য দ্রুত বর্ধনশীল বাজারে এলএলএম-এর সম্ভাবনা প্রতিফলিত হয়। বিশ্লেষকরা এনএলপি বাজার থেকে প্রসারিত হতে প্রজেক্ট করেন 11 সালে $2020 বিলিয়ন থেকে 35 সালের মধ্যে $2026 বিলিয়ন ছাড়িয়ে যাবে. তবে এটি কেবল বাজারের আকার নয় যা প্রসারিত হচ্ছে। মডেলগুলি নিজেরাও ক্রমবর্ধমান হয়, উভয় শারীরিক আকারে এবং তারা পরিচালনা করে এমন পরামিতিগুলির সংখ্যায়। বছরের পর বছর ধরে এলএলএম-এর বিবর্তন, যেমনটি নীচের চিত্রে দেখা গেছে (ছবির উত্স: লিঙ্ক), তাদের ক্রমবর্ধমান জটিলতা এবং ক্ষমতাকে আন্ডারস্কোর করে।
বড় ভাষার মডেলের জনপ্রিয় ব্যবহারের ক্ষেত্রে
এখানে এলএলএম-এর কিছু শীর্ষ এবং সর্বাধিক প্রচলিত ব্যবহারের ক্ষেত্রে রয়েছে:
- প্রাকৃতিক ভাষার পাঠ্য তৈরি করা হচ্ছে: লার্জ ল্যাঙ্গুয়েজ মডেল (LLMs) কৃত্রিম বুদ্ধিমত্তা এবং কম্পিউটেশনাল ভাষাতত্ত্বের শক্তিকে একত্রিত করে স্বায়ত্তশাসিতভাবে প্রাকৃতিক ভাষায় পাঠ্য তৈরি করে। তারা বিভিন্ন ব্যবহারকারীর চাহিদা পূরণ করতে পারে যেমন নিবন্ধ লেখা, গান তৈরি করা বা ব্যবহারকারীদের সাথে কথোপকথনে জড়িত।
- মেশিনের মাধ্যমে অনুবাদ: যেকোন জোড়া ভাষার মধ্যে টেক্সট অনুবাদ করার জন্য এলএলএম কার্যকরভাবে কাজে লাগানো যেতে পারে। এই মডেলগুলি উত্স এবং লক্ষ্য উভয় ভাষার ভাষাগত কাঠামো বোঝার জন্য পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলির মতো গভীর শিক্ষার অ্যালগরিদমগুলিকে কাজে লাগায়, যার ফলে উত্স পাঠ্যের পছন্দসই ভাষায় অনুবাদের সুবিধা হয়৷
- মূল বিষয়বস্তু তৈরি করা: এলএলএমগুলি মেশিনগুলির জন্য সুসংহত এবং যৌক্তিক বিষয়বস্তু তৈরি করার পথ খুলে দিয়েছে। এই সামগ্রীটি ব্লগ পোস্ট, নিবন্ধ এবং অন্যান্য ধরণের সামগ্রী তৈরি করতে ব্যবহার করা যেতে পারে। মডেলগুলি একটি উপন্যাস এবং ব্যবহারকারী-বান্ধব পদ্ধতিতে বিষয়বস্তু বিন্যাস এবং গঠন করতে তাদের গভীর-শিক্ষার অভিজ্ঞতায় ট্যাপ করে।
- অনুভূতি বিশ্লেষণ: বৃহৎ ভাষার মডেলের একটি কৌতুহলপূর্ণ প্রয়োগ হল অনুভূতি বিশ্লেষণ। এতে, মডেলটিকে টীকাকৃত পাঠে উপস্থিত মানসিক অবস্থা এবং অনুভূতিগুলি সনাক্ত করতে এবং শ্রেণিবদ্ধ করতে প্রশিক্ষণ দেওয়া হয়। সফ্টওয়্যারটি ইতিবাচকতা, নেতিবাচকতা, নিরপেক্ষতা এবং অন্যান্য জটিল অনুভূতির মতো আবেগগুলি সনাক্ত করতে পারে। এটি গ্রাহকদের প্রতিক্রিয়া এবং বিভিন্ন পণ্য এবং পরিষেবা সম্পর্কে মতামতের মূল্যবান অন্তর্দৃষ্টি প্রদান করতে পারে।
- পাঠ্য বোঝা, সংক্ষিপ্তকরণ এবং শ্রেণিবদ্ধকরণ: এলএলএম টেক্সট এবং এর প্রেক্ষাপট ব্যাখ্যা করার জন্য এআই সফ্টওয়্যারের জন্য একটি কার্যকর কাঠামো স্থাপন করে। বিপুল পরিমাণ ডেটা বোঝার এবং যাচাই করার জন্য মডেলকে নির্দেশ দিয়ে, এলএলএমগুলি এআই মডেলগুলিকে বিভিন্ন ফর্ম এবং প্যাটার্নে পাঠ্যকে বোঝা, সংক্ষিপ্তকরণ এবং এমনকি শ্রেণিবদ্ধ করতে সক্ষম করে।
- প্রশ্নের উত্তর দিচ্ছি: বৃহৎ ভাষার মডেলগুলি ব্যবহারকারীর স্বাভাবিক ভাষা প্রশ্নের সঠিকভাবে উপলব্ধি করতে এবং উত্তর দেওয়ার ক্ষমতা সহ প্রশ্ন উত্তর (QA) সিস্টেমগুলিকে সজ্জিত করে। এই ব্যবহারের ক্ষেত্রে জনপ্রিয় উদাহরণগুলির মধ্যে রয়েছে ChatGPT এবং BERT, যা একটি প্রশ্নের প্রেক্ষাপট পরীক্ষা করে এবং ব্যবহারকারীর প্রশ্নগুলির প্রাসঙ্গিক প্রতিক্রিয়া প্রদানের জন্য পাঠ্যের একটি বিশাল সংগ্রহের মাধ্যমে পরীক্ষা করে।

পার্ট-অফ-স্পীচ (POS) ট্যাগিং
বাক্যে শব্দগুলিকে তাদের ব্যাকরণগত ফাংশনের সাথে ট্যাগ করা হয়, যেমন ক্রিয়া, বিশেষ্য, বিশেষণ ইত্যাদি। এই প্রক্রিয়াটি মডেলটিকে ব্যাকরণ এবং শব্দের মধ্যে যোগসূত্র বুঝতে সহায়তা করে।

নামকৃত সত্তা স্বীকৃতি (NER)
একটি বাক্যের মধ্যে সংগঠন, অবস্থান এবং ব্যক্তিদের মত নামকৃত সত্তা চিহ্নিত করা হয়। এই অনুশীলনটি শব্দ এবং বাক্যাংশের শব্দার্থিক অর্থ ব্যাখ্যা করতে মডেলটিকে সহায়তা করে এবং আরও সুনির্দিষ্ট প্রতিক্রিয়া প্রদান করে।

অনুভূতির বিশ্লেষণ
টেক্সট ডেটাতে ইতিবাচক, নিরপেক্ষ বা নেতিবাচক মত অনুভূতির লেবেল বরাদ্দ করা হয়, যা মডেলকে বাক্যের আবেগগত আন্ডারটোন বুঝতে সাহায্য করে। আবেগ এবং মতামত জড়িত প্রশ্নের উত্তর দিতে এটি বিশেষভাবে কার্যকর।
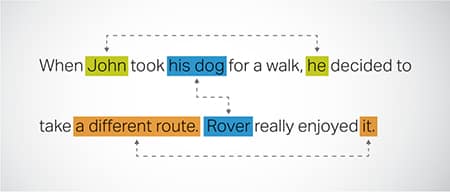
কোরফারেন্স রেজোলিউশন
একটি পাঠ্যের বিভিন্ন অংশে একই সত্তা উল্লেখ করা হয় এমন উদাহরণগুলি সনাক্ত করা এবং সমাধান করা। এই পদক্ষেপটি মডেলটিকে বাক্যের প্রেক্ষাপট বুঝতে সাহায্য করে, এইভাবে সুসংগত প্রতিক্রিয়ার দিকে পরিচালিত করে।
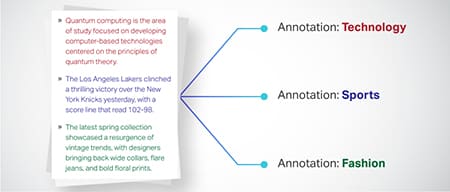
পাঠ্য শ্রেণিবিন্যাস
টেক্সট ডেটা পণ্য পর্যালোচনা বা সংবাদ নিবন্ধের মতো পূর্বনির্ধারিত গ্রুপে শ্রেণীবদ্ধ করা হয়। এটি মডেলটিকে পাঠ্যের ধরণ বা বিষয় বুঝতে, আরও প্রাসঙ্গিক প্রতিক্রিয়া তৈরি করতে সহায়তা করে।
শাইপের অফার
শিপ সংস্থাগুলিকে তাদের ডেটা পরিচালনা, বিশ্লেষণ এবং সর্বাধিক ব্যবহার করতে সহায়তা করার জন্য বিস্তৃত পরিষেবা সরবরাহ করে৷
ডেটা ওয়েব-স্ক্র্যাপিং
Shaip দ্বারা অফার করা একটি মূল পরিষেবা হ'ল ডেটা স্ক্র্যাপিং। এটি ডোমেন-নির্দিষ্ট URL থেকে ডেটা নিষ্কাশন জড়িত। স্বয়ংক্রিয় সরঞ্জাম এবং কৌশলগুলি ব্যবহার করে, Shaip দ্রুত এবং দক্ষতার সাথে বিভিন্ন ওয়েবসাইট, পণ্য ম্যানুয়াল, প্রযুক্তিগত ডকুমেন্টেশন, অনলাইন ফোরাম, অনলাইন পর্যালোচনা, গ্রাহক পরিষেবা ডেটা, শিল্প নিয়ন্ত্রক নথি ইত্যাদি থেকে প্রচুর পরিমাণে ডেটা স্ক্র্যাপ করতে পারে৷ এই প্রক্রিয়াটি ব্যবসার জন্য অমূল্য হতে পারে যখন অনেকগুলি উত্স থেকে প্রাসঙ্গিক এবং নির্দিষ্ট ডেটা সংগ্রহ করা।

যন্ত্রানুবাদ
বিভিন্ন ভাষায় পাঠ্য অনুবাদের জন্য সংশ্লিষ্ট ট্রান্সক্রিপশনের সাথে যুক্ত বিস্তৃত বহুভাষিক ডেটাসেট ব্যবহার করে মডেল তৈরি করুন। এই প্রক্রিয়াটি ভাষাগত বাধা দূর করতে সাহায্য করে এবং তথ্যের অ্যাক্সেসযোগ্যতাকে উৎসাহিত করে।
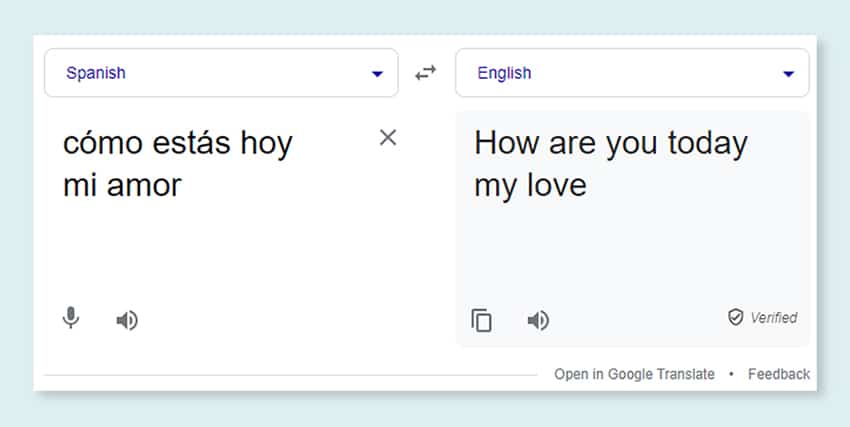
শ্রেণীবিন্যাস নিষ্কাশন এবং সৃষ্টি
Shaip শ্রেণীবিন্যাস নিষ্কাশন এবং সৃষ্টিতে সাহায্য করতে পারে। এটি একটি কাঠামোগত বিন্যাসে ডেটা শ্রেণীবদ্ধ এবং শ্রেণীবদ্ধ করে যা বিভিন্ন ডেটা পয়েন্টের মধ্যে সম্পর্ককে প্রতিফলিত করে। এটি ব্যবসার জন্য তাদের ডেটা সংগঠিত করার জন্য বিশেষভাবে উপযোগী হতে পারে, এটি আরও অ্যাক্সেসযোগ্য এবং বিশ্লেষণ করা সহজ করে তোলে। উদাহরণস্বরূপ, একটি ই-কমার্স ব্যবসায়, পণ্যের ডেটা পণ্যের ধরন, ব্র্যান্ড, মূল্য ইত্যাদির উপর ভিত্তি করে শ্রেণীবদ্ধ করা যেতে পারে, যা গ্রাহকদের পণ্য ক্যাটালগ নেভিগেট করা সহজ করে তোলে।
তথ্য সংগ্রহ
আমাদের ডেটা সংগ্রহ পরিষেবাগুলি জেনারেটিভ এআই অ্যালগরিদম প্রশিক্ষণ এবং আপনার মডেলগুলির নির্ভুলতা এবং কার্যকারিতা উন্নত করার জন্য প্রয়োজনীয় সমালোচনামূলক বাস্তব-জগত বা সিন্থেটিক ডেটা সরবরাহ করে। ডেটা গোপনীয়তা এবং সুরক্ষার কথা মাথায় রেখে ডেটা নিরপেক্ষ, নৈতিকভাবে এবং দায়িত্বের সাথে সংগ্রহ করা হয়।

প্রশ্ন ও উত্তর
প্রশ্ন উত্তর (QA) প্রাকৃতিক ভাষা প্রক্রিয়াকরণের একটি উপক্ষেত্র যা মানুষের ভাষায় স্বয়ংক্রিয়ভাবে প্রশ্নের উত্তর দেওয়ার উপর দৃষ্টি নিবদ্ধ করে। QA সিস্টেমগুলিকে বিস্তৃত পাঠ্য এবং কোডের উপর প্রশিক্ষিত করা হয়, যা তাদের বিভিন্ন ধরণের প্রশ্নগুলি পরিচালনা করতে সক্ষম করে, যার মধ্যে রয়েছে বাস্তব, সংজ্ঞামূলক এবং মতামত-ভিত্তিক প্রশ্নগুলি। কাস্টমার সাপোর্ট, হেলথ কেয়ার বা সাপ্লাই চেইনের মতো নির্দিষ্ট ক্ষেত্রের জন্য তৈরি QA মডেল তৈরির জন্য ডোমেন জ্ঞান অত্যন্ত গুরুত্বপূর্ণ। যাইহোক, জেনারেটিভ QA পন্থা মডেলগুলিকে শুধুমাত্র প্রেক্ষাপটের উপর নির্ভর করে ডোমেন জ্ঞান ছাড়াই পাঠ্য তৈরি করতে দেয়।
আমাদের বিশেষজ্ঞদের দল সতর্কতার সাথে প্রশ্ন-উত্তর জোড়া তৈরি করতে ব্যাপক নথি বা ম্যানুয়াল অধ্যয়ন করতে পারে, যা ব্যবসার জন্য জেনারেটিভ এআই তৈরির সুবিধা দেয়। এই পদ্ধতি কার্যকরভাবে একটি বিস্তৃত কর্পাস থেকে প্রাসঙ্গিক তথ্য খনির মাধ্যমে ব্যবহারকারীর অনুসন্ধানগুলিকে মোকাবেলা করতে পারে। আমাদের প্রত্যয়িত বিশেষজ্ঞরা বিভিন্ন বিষয় এবং ডোমেন জুড়ে বিস্তৃত উচ্চ-মানের প্রশ্নোত্তর জোড়ার উৎপাদন নিশ্চিত করেন।

পাঠ্য সংক্ষিপ্তকরণ
আমাদের বিশেষজ্ঞরা ব্যাপক কথোপকথন বা দীর্ঘ কথোপকথন ডিস্টিল করতে, বিস্তৃত পাঠ্য ডেটা থেকে সংক্ষিপ্ত এবং অন্তর্দৃষ্টিপূর্ণ সারসংক্ষেপ সরবরাহ করতে সক্ষম।

টেক্সট জেনারেশন
সংবাদ নিবন্ধ, কথাসাহিত্য এবং কবিতার মতো বিভিন্ন শৈলীতে পাঠ্যের বিস্তৃত ডেটাসেট ব্যবহার করে মডেলদের প্রশিক্ষণ দিন। এই মডেলগুলি তারপরে বিভিন্ন ধরণের সামগ্রী তৈরি করতে পারে, যার মধ্যে সংবাদের টুকরো, ব্লগ এন্ট্রি বা সোশ্যাল মিডিয়া পোস্টগুলি রয়েছে, যা সামগ্রী তৈরির জন্য একটি সাশ্রয়ী এবং সময় সাশ্রয়ী সমাধান প্রদান করে৷
কন্ঠ সনান্তকরণ
বিভিন্ন অ্যাপ্লিকেশনের জন্য কথ্য ভাষা বুঝতে সক্ষম মডেলগুলি তৈরি করুন। এতে ভয়েস-অ্যাক্টিভেটেড অ্যাসিস্ট্যান্ট, ডিক্টেশন সফ্টওয়্যার এবং রিয়েল-টাইম অনুবাদ টুল অন্তর্ভুক্ত রয়েছে। এই প্রক্রিয়ার মধ্যে কথ্য ভাষার অডিও রেকর্ডিং সমন্বিত একটি ব্যাপক ডেটাসেট ব্যবহার করা জড়িত, যা তাদের সংশ্লিষ্ট প্রতিলিপিগুলির সাথে যুক্ত।

পণ্য সুপারিশ
গ্রাহক কেনার ইতিহাসের ব্যাপক ডেটাসেট ব্যবহার করে মডেলগুলি তৈরি করুন, যার মধ্যে লেবেলগুলি রয়েছে যা নির্দেশ করে যে পণ্যগুলি গ্রাহকরা ক্রয় করতে আগ্রহী৷ লক্ষ্য হল গ্রাহকদের সুনির্দিষ্ট পরামর্শ প্রদান করা, যার ফলে বিক্রয় বৃদ্ধি করা এবং গ্রাহকের সন্তুষ্টি বৃদ্ধি করা।
ছবির ক্যাপশনিং
আমাদের অত্যাধুনিক, এআই-চালিত ইমেজ ক্যাপশনিং পরিষেবার মাধ্যমে আপনার ছবি ব্যাখ্যার প্রক্রিয়াকে পরিবর্তন করুন। আমরা নির্ভুল এবং প্রাসঙ্গিকভাবে অর্থপূর্ণ বর্ণনা তৈরি করে ছবিগুলিতে প্রাণশক্তি যোগ করি। এটি আপনার দর্শকদের জন্য আপনার ভিজ্যুয়াল সামগ্রীর সাথে উদ্ভাবনী ব্যস্ততা এবং মিথস্ক্রিয়া সম্ভাবনার পথ তৈরি করে।

টেক্সট-টু-স্পিচ পরিষেবা প্রশিক্ষণ
আমরা মানুষের বক্তৃতা অডিও রেকর্ডিং সমন্বিত একটি বিস্তৃত ডেটাসেট প্রদান করি, যা এআই মডেলের প্রশিক্ষণের জন্য আদর্শ। এই মডেলগুলি আপনার অ্যাপ্লিকেশনগুলির জন্য প্রাকৃতিক এবং আকর্ষক ভয়েস তৈরি করতে সক্ষম, এইভাবে আপনার ব্যবহারকারীদের জন্য একটি স্বতন্ত্র এবং নিমজ্জিত শব্দ অভিজ্ঞতা প্রদান করে৷



