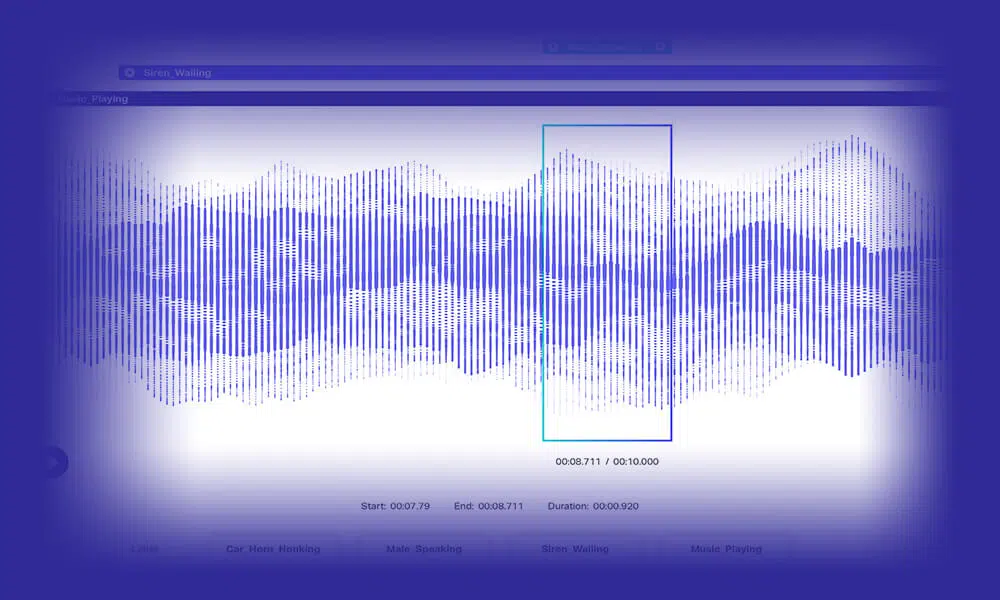


অডিও ট্রান্সক্রিপশন
সুনির্দিষ্টভাবে প্রতিলিপিকৃত বক্তৃতা/অডিও ডেটার ট্রাকলোডে খাওয়ানোর মাধ্যমে বুদ্ধিমান NLP মডেলগুলি বিকাশ করুন। Shaip-এ, আমরা আপনাকে স্ট্যান্ডার্ড অডিও, শব্দচয়ন এবং বহুভাষিক ট্রান্সক্রিপশন সহ আরও বিস্তৃত পছন্দের সেট থেকে বেছে নিতে দিই। এছাড়াও, আপনি অতিরিক্ত স্পিকার শনাক্তকারী এবং সময়-স্ট্যাম্পিং ডেটা সহ মডেলগুলিকে প্রশিক্ষণ দিতে পারেন।
স্পিচ লেবেলিং
স্পিচ বা অডিও লেবেলিং হল একটি স্ট্যান্ডার্ড টীকা কৌশল যা শব্দ আলাদা করা এবং নির্দিষ্ট মেটাডেটা দিয়ে লেবেল করার বিষয়। এই কৌশলটির সারমর্মের মধ্যে রয়েছে অডিওর একটি অংশ থেকে শব্দের অনটোলজিকাল সনাক্তকরণ এবং প্রশিক্ষণ ডেটাসেটগুলিকে আরও অন্তর্ভুক্ত করার জন্য সঠিকভাবে টীকা করা।

অডিও শ্রেণীবিভাগ
এটি বক্তৃতা টীকা সংস্থাগুলি দ্বারা AI-কে পরিপূর্ণতার জন্য প্রশিক্ষণের জন্য ব্যবহার করা হয়, বিষয়বস্তু অনুসারে অডিও রেকর্ডিং বিশ্লেষণের উদ্বেগ। অডিও শ্রেণীবিভাগের সাহায্যে, মেশিনগুলি ভয়েস এবং শব্দ সনাক্ত করতে পারে, যখন আরও সক্রিয় প্রশিক্ষণ ব্যবস্থার অংশ হিসাবে দুটির মধ্যে পার্থক্য করতে সক্ষম হয়।

বহুভাষিক অডিও ডেটা পরিষেবা
বহুভাষিক অডিও ডেটা সংগ্রহ করা তখনই উপযোগী যদি টীকাকাররা সে অনুযায়ী লেবেল এবং সেগমেন্ট করতে পারে। এখানেই বহুভাষিক অডিও ডেটা পরিষেবাগুলি কাজে আসে কারণ তারা ভাষার বৈচিত্র্যের উপর ভিত্তি করে বক্তৃতা টীকা করার বিষয়ে উদ্বেগ প্রকাশ করে, যাতে প্রাসঙ্গিক AI দ্বারা চিহ্নিত করা যায় এবং পুরোপুরি পার্স করা যায়।

স্বভাবিক ভাষা
উচ্চারণ
NLU ক্ষুদ্রতম বিবরণ যেমন শব্দার্থবিদ্যা, উপভাষা, প্রসঙ্গ, চাপ এবং আরও অনেক কিছুকে শ্রেণীবদ্ধ করার জন্য মানুষের বক্তৃতাকে টীকা দেওয়ার বিষয়ে উদ্বেগ প্রকাশ করে। ভার্চুয়াল সহকারী এবং চ্যাটবটগুলিকে আরও ভাল প্রশিক্ষণ দেওয়ার ক্ষেত্রে টীকাযুক্ত ডেটার এই ফর্মটি বোঝা যায়৷
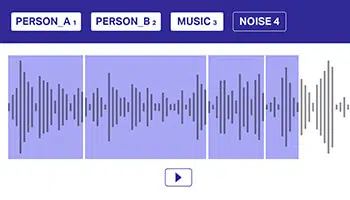
মাল্টি-লেবেল
টীকা
মডেলগুলিকে ওভারল্যাপিং অডিও উত্সগুলিকে আলাদা করতে সাহায্য করার জন্য একাধিক লেবেল অবলম্বন করে অডিও ডেটা টীকা করা গুরুত্বপূর্ণ৷ এই পদ্ধতিতে, একটি অডিও ডেটাসেট এক বা একাধিক শ্রেণীর অন্তর্গত হতে পারে, যা ভাল সিদ্ধান্ত নেওয়ার জন্য মডেলের কাছে স্পষ্টভাবে জানানো প্রয়োজন।

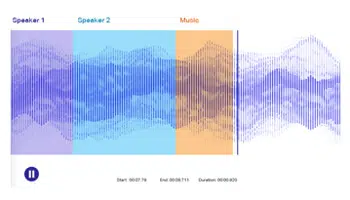
স্পিকার ডায়েরাইজেশন
এটি একটি ইনপুট অডিও ফাইলকে পৃথক স্পিকারের সাথে যুক্ত সমজাতীয় বিভাগে বিভক্ত করে। ডায়েরাইজেশন মানে স্পিকারের সীমানা চিহ্নিত করা এবং স্বতন্ত্র স্পিকারের সংখ্যা নির্ধারণ করতে অডিও ফাইলগুলিকে সেগমেন্টে গোষ্ঠীবদ্ধ করা। এই প্রক্রিয়া স্বয়ংক্রিয়ভাবে কথোপকথন বিশ্লেষণ এবং কল সেন্টার কথোপকথন, চিকিৎসা এবং আইনি কথোপকথন এবং মিটিং এর প্রতিলিপি করতে সাহায্য করে।

ফোনেটিক ট্রান্সক্রিপশন
নিয়মিত ট্রান্সক্রিপশনের বিপরীতে যা অডিওকে শব্দের ক্রমানুসারে রূপান্তর করে, একটি ফোনেটিক ট্রান্সক্রিপশন নোট করে যে কীভাবে শব্দগুলি উচ্চারিত হয় এবং ধ্বনিগত প্রতীক ব্যবহার করে শব্দগুলিকে দৃশ্যমানভাবে উপস্থাপন করে। ফোনেটিক ট্রান্সক্রিপশন বিভিন্ন উপভাষায় একই ভাষার উচ্চারণের পার্থক্য লক্ষ্য করা সহজ করে তোলে।

সম্প্রদায়
নিবেদিত এবং প্রশিক্ষিত দল:
- ডেটা তৈরি, লেবেলিং এবং QA-এর জন্য 30,000+ সহযোগী
- শংসাপত্রযুক্ত প্রকল্প ব্যবস্থাপনা দল
- অভিজ্ঞ পণ্য উন্নয়ন দল
- ট্যালেন্ট পুল সোর্সিং এবং অনবোর্ডিং দল

প্রক্রিয়া
সর্বোচ্চ প্রক্রিয়া দক্ষতা নিশ্চিত করা হয়:
- শক্তিশালী 6 সিগমা স্টেজ-গেট প্রক্রিয়া
- 6টি সিগমা ব্ল্যাক বেল্টের একটি উত্সর্গীকৃত দল - মূল প্রক্রিয়ার মালিক এবং গুণমান সম্মতি
- ক্রমাগত উন্নতি এবং প্রতিক্রিয়া লুপ

প্ল্যাটফর্ম
পেটেন্ট প্ল্যাটফর্ম সুবিধা প্রদান করে:
- ওয়েব-ভিত্তিক এন্ড-টু-এন্ড প্ল্যাটফর্ম
- অনবদ্য গুণমান
- দ্রুত TAT
- বিরামহীন ডেলিভারি
সম্প্রদায়
নিবেদিত এবং প্রশিক্ষিত দল:
- ডেটা তৈরি, লেবেলিং এবং QA-এর জন্য 30,000+ সহযোগী
- শংসাপত্রযুক্ত প্রকল্প ব্যবস্থাপনা দল
- অভিজ্ঞ পণ্য উন্নয়ন দল
- ট্যালেন্ট পুল সোর্সিং এবং অনবোর্ডিং দল
প্রক্রিয়া
সর্বোচ্চ প্রক্রিয়া দক্ষতা নিশ্চিত করা হয়:
- শক্তিশালী 6 সিগমা স্টেজ-গেট প্রক্রিয়া
- 6টি সিগমা ব্ল্যাক বেল্টের একটি উত্সর্গীকৃত দল - মূল প্রক্রিয়ার মালিক এবং গুণমান সম্মতি
- ক্রমাগত উন্নতি এবং প্রতিক্রিয়া লুপ
প্ল্যাটফর্ম
পেটেন্ট প্ল্যাটফর্ম সুবিধা প্রদান করে:
- ওয়েব-ভিত্তিক এন্ড-টু-এন্ড প্ল্যাটফর্ম
- অনবদ্য গুণমান
- দ্রুত TAT
- বিরামহীন ডেলিভারি

পাঠ্য টীকা
সেবা
আমরা সত্তা টীকা, পাঠ্য শ্রেণিবিন্যাস, অনুভূতি টীকা এবং অন্যান্য প্রাসঙ্গিক সরঞ্জামগুলি ব্যবহার করে সম্পূর্ণ ডেটাসেটগুলি টীকা করে পাঠ্য ডেটা প্রশিক্ষণ প্রস্তুত করতে বিশেষজ্ঞ।

চিত্র টিকা
সেবা
আমরা লেবেলিং, সেগমেন্টেড ইমেজ ডেটাসেট কম্পিউটার ভিশন মডেল প্রশিক্ষণের জন্য গর্ব করি। কিছু প্রাসঙ্গিক কৌশলের মধ্যে রয়েছে সীমানা স্বীকৃতি এবং চিত্র শ্রেণীবিভাগ।

ভিডিও টীকা
সেবা
Shaip কম্পিউটার ভিশন মডেল প্রশিক্ষণের জন্য উচ্চ-সম্পন্ন ভিডিও লেবেলিং পরিষেবা সরবরাহ করে। উদ্দেশ্য হল প্যাটার্ন শনাক্তকরণ, অবজেক্ট ডিটেকশন এবং আরও অনেক কিছুর সাহায্যে ডেটাসেটগুলিকে ব্যবহারযোগ্য করে তোলা।


