
কৃত্রিম বুদ্ধিমত্তা এবং বিগ ডেটা স্থানীয় সমস্যাগুলিকে অগ্রাধিকার দেওয়ার এবং অনেক গভীর উপায়ে বিশ্বকে রূপান্তর করার সময় বিশ্বব্যাপী সমস্যার সমাধান খুঁজে পাওয়ার সম্ভাবনা রয়েছে। AI সকলের জন্য সমাধান নিয়ে আসে – এবং সমস্ত সেটিংসে, বাড়ি থেকে কর্মক্ষেত্রে। এআই কম্পিউটার সহ মেশিন লার্নিং প্রশিক্ষণ, একটি স্বয়ংক্রিয় কিন্তু ব্যক্তিগতকৃত পদ্ধতিতে বুদ্ধিমান আচরণ এবং কথোপকথন অনুকরণ করতে পারে।
তবুও, এআই একটি অন্তর্ভুক্তি সমস্যার সম্মুখীন হয় এবং প্রায়শই পক্ষপাতদুষ্ট হয়। সৌভাগ্যবশত, উপর ফোকাস কৃত্রিম বুদ্ধিমত্তা নীতিশাস্ত্র বিভিন্ন প্রশিক্ষণ তথ্যের মাধ্যমে অচেতন পক্ষপাত দূর করে বৈচিত্র্যকরণ এবং অন্তর্ভুক্তির ক্ষেত্রে নতুন সম্ভাবনার সূচনা করতে পারে।
এআই প্রশিক্ষণের ডেটাতে বৈচিত্র্যের গুরুত্ব
 প্রশিক্ষণ ডেটার বৈচিত্র্য এবং গুণমান সম্পর্কিত কারণ একটি অন্যটিকে প্রভাবিত করে এবং এআই সমাধানের ফলাফলকে প্রভাবিত করে। AI সমাধানের সাফল্য নির্ভর করে এর উপর বিভিন্ন তথ্য এটা প্রশিক্ষিত হয়. ডেটা বৈচিত্র্য AI-কে ওভারফিটিং থেকে বাধা দেয় - মানে মডেলটি শুধুমাত্র প্রশিক্ষণের জন্য ব্যবহৃত ডেটা থেকে পারফর্ম করে বা শেখে। ওভারফিটিং সহ, প্রশিক্ষণে ব্যবহৃত না হওয়া ডেটার উপর পরীক্ষা করার সময় AI মডেল ফলাফল প্রদান করতে পারে না।
প্রশিক্ষণ ডেটার বৈচিত্র্য এবং গুণমান সম্পর্কিত কারণ একটি অন্যটিকে প্রভাবিত করে এবং এআই সমাধানের ফলাফলকে প্রভাবিত করে। AI সমাধানের সাফল্য নির্ভর করে এর উপর বিভিন্ন তথ্য এটা প্রশিক্ষিত হয়. ডেটা বৈচিত্র্য AI-কে ওভারফিটিং থেকে বাধা দেয় - মানে মডেলটি শুধুমাত্র প্রশিক্ষণের জন্য ব্যবহৃত ডেটা থেকে পারফর্ম করে বা শেখে। ওভারফিটিং সহ, প্রশিক্ষণে ব্যবহৃত না হওয়া ডেটার উপর পরীক্ষা করার সময় AI মডেল ফলাফল প্রদান করতে পারে না।
এআই প্রশিক্ষণের বর্তমান অবস্থা উপাত্ত
ডেটাতে অসমতা বা বৈচিত্র্যের অভাব অন্যায্য, অনৈতিক এবং অ-অন্তর্ভুক্ত AI সমাধানের দিকে পরিচালিত করবে যা বৈষম্যকে আরও গভীর করতে পারে। কিন্তু কীভাবে এবং কেন ডেটার বৈচিত্র্য AI সমাধানগুলির সাথে সম্পর্কিত?
সমস্ত শ্রেণীর অসম প্রতিনিধিত্ব মুখের ভুল শনাক্তকরণের দিকে পরিচালিত করে - একটি গুরুত্বপূর্ণ ঘটনা হল Google ফটো যা একটি কালো দম্পতিকে 'গরিলা' হিসাবে শ্রেণীবদ্ধ করেছে৷ এবং মেটা একজন ব্যবহারকারীকে কালো পুরুষদের ভিডিও দেখার অনুরোধ জানায় ব্যবহারকারী 'প্রাইমেটদের ভিডিও দেখা চালিয়ে যেতে' চান কিনা।
উদাহরণস্বরূপ, জাতিগত বা জাতিগত সংখ্যালঘুদের ভুল বা অনুপযুক্ত শ্রেণীবিভাগ, বিশেষ করে চ্যাটবটগুলিতে, এআই প্রশিক্ষণ ব্যবস্থায় কুসংস্কারের কারণ হতে পারে। 2019 সালের রিপোর্ট অনুযায়ী বৈষম্যমূলক ব্যবস্থা - লিঙ্গ, জাতি, এআই-এ শক্তি, AI এর 80% এরও বেশি শিক্ষক পুরুষ; FB-তে নারী AI গবেষকদের সংখ্যা মাত্র 15% এবং Google-এ 10%।
এআই পারফরম্যান্সের উপর বিভিন্ন প্রশিক্ষণ ডেটার প্রভাব
 ডেটা উপস্থাপনা থেকে নির্দিষ্ট গোষ্ঠী এবং সম্প্রদায়গুলিকে বাদ দিলে তির্যক অ্যালগরিদম হতে পারে।
ডেটা উপস্থাপনা থেকে নির্দিষ্ট গোষ্ঠী এবং সম্প্রদায়গুলিকে বাদ দিলে তির্যক অ্যালগরিদম হতে পারে।
ডেটা পক্ষপাত প্রায়শই দুর্ঘটনাক্রমে ডেটা সিস্টেমে প্রবর্তিত হয় - নির্দিষ্ট জাতি বা গোষ্ঠীর আন্ডার-স্যাম্পলিংয়ের মাধ্যমে। যখন মুখের শনাক্তকরণ সিস্টেমগুলি বিভিন্ন মুখের উপর প্রশিক্ষিত হয়, এটি মডেলটিকে নির্দিষ্ট বৈশিষ্ট্যগুলি সনাক্ত করতে সাহায্য করে, যেমন মুখের অঙ্গগুলির অবস্থান এবং রঙের বৈচিত্র।
লেবেলগুলির একটি ভারসাম্যহীন ফ্রিকোয়েন্সি থাকার আরেকটি ফলাফল হল যে সিস্টেমটি একটি সংখ্যালঘুকে একটি অসঙ্গতি হিসাবে বিবেচনা করতে পারে যখন অল্প সময়ের মধ্যে একটি আউটপুট তৈরি করার জন্য চাপ দেওয়া হয়।
এআই ট্রেনিং ডেটাতে বৈচিত্র্য অর্জন করা
অন্যদিকে, একটি বৈচিত্র্যময় ডেটাসেট তৈরি করাও একটি চ্যালেঞ্জ। নির্দিষ্ট শ্রেণীতে তথ্যের নিছক অভাব নিম্ন-প্রতিনিধিত্বের দিকে নিয়ে যেতে পারে। দক্ষতা, জাতি, জাতি, লিঙ্গ, শৃঙ্খলা এবং আরও অনেক কিছুর ক্ষেত্রে এআই বিকাশকারী দলগুলিকে আরও বৈচিত্র্যময় করে এটি প্রশমিত করা যেতে পারে। তদুপরি, AI-তে ডেটা বৈচিত্র্যের সমস্যাগুলি মোকাবেলার আদর্শ উপায় হ'ল যা করা হয়েছে তা ঠিক করার চেষ্টা করার পরিবর্তে গো শব্দ থেকে এটির মোকাবিলা করা - ডেটা সংগ্রহ এবং কিউরেশন পর্যায়ে বৈচিত্র্য আনা।
AI এর চারপাশে যতই হাইপ থাকুক না কেন, এটি এখনও মানুষের দ্বারা সংগৃহীত, নির্বাচিত এবং প্রশিক্ষিত ডেটার উপর নির্ভর করে। মানুষের সহজাত পক্ষপাত তাদের দ্বারা সংগৃহীত ডেটাতে প্রতিফলিত হবে এবং এই অসচেতন পক্ষপাতটি এমএল মডেলগুলিতেও ছড়িয়ে পড়ে।
বিভিন্ন প্রশিক্ষণের তথ্য সংগ্রহ ও কিউরেট করার পদক্ষেপ
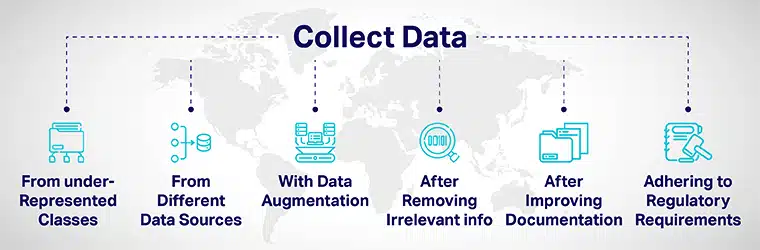
ডেটা বৈচিত্র্য দ্বারা অর্জন করা যেতে পারে:
- ভেবেচিন্তে আন্ডার-প্রেজেন্টেড ক্লাস থেকে আরও ডেটা যোগ করুন এবং আপনার মডেলগুলিকে বিভিন্ন ডেটা পয়েন্টে প্রকাশ করুন।
- বিভিন্ন তথ্য উৎস থেকে তথ্য সংগ্রহ করে।
- ডেটা বৃদ্ধির মাধ্যমে বা কৃত্রিমভাবে ডেটাসেটগুলিকে ম্যানিপুলেট করে নতুন ডেটা পয়েন্টগুলিকে মূল ডেটা পয়েন্ট থেকে আলাদাভাবে বৃদ্ধি/অন্তর্ভুক্ত করতে।
- AI বিকাশ প্রক্রিয়ার জন্য আবেদনকারীদের নিয়োগ করার সময়, আবেদন থেকে সমস্ত চাকরি-অপ্রাসঙ্গিক তথ্য মুছে ফেলুন।
- মডেলগুলির উন্নয়ন এবং মূল্যায়নের ডকুমেন্টেশন উন্নত করে স্বচ্ছতা এবং জবাবদিহিতা উন্নত করা।
- বৈচিত্র্য তৈরির জন্য প্রবিধান প্রবর্তন এবং AI-তে অন্তর্ভুক্তি তৃণমূল পর্যায় থেকে সিস্টেম। বিভিন্ন সরকার বৈচিত্র্য নিশ্চিত করতে এবং এআই পক্ষপাত কমানোর জন্য নির্দেশিকা তৈরি করেছে যা অন্যায্য ফলাফল দিতে পারে।
[এছাড়াও পড়ুন: এআই প্রশিক্ষণের ডেটা সংগ্রহ প্রক্রিয়া সম্পর্কে আরও জানুন ]
উপসংহার
বর্তমানে, শুধুমাত্র কয়েকটি বড় প্রযুক্তি কোম্পানি এবং শিক্ষা কেন্দ্র একচেটিয়াভাবে এআই সমাধান তৈরিতে জড়িত। এই অভিজাত স্থানগুলি বর্জন, বৈষম্য এবং পক্ষপাতের মধ্যে নিমজ্জিত। যাইহোক, এগুলি হল সেই জায়গা যেখানে AI তৈরি করা হচ্ছে, এবং এই উন্নত AI সিস্টেমগুলির পিছনে যুক্তি একই পক্ষপাত, বৈষম্য এবং বর্জন দ্বারা পরিপূর্ণ যা নিম্ন প্রতিনিধিত্বকারী গোষ্ঠীগুলি বহন করে।
বৈচিত্র্য এবং অ-বৈষম্য নিয়ে আলোচনা করার সময়, এটির উপকারিতা এবং ক্ষতিকারকদের প্রশ্ন করা গুরুত্বপূর্ণ। আমাদের এটাও দেখা উচিত যে এটি কাকে অসুবিধায় ফেলে - একজন 'স্বাভাবিক' ব্যক্তির ধারণা জোর করে, AI সম্ভাব্যভাবে 'অন্যদের' ঝুঁকিতে ফেলতে পারে।
শক্তি সম্পর্ক, ইক্যুইটি এবং ন্যায়বিচারকে স্বীকার না করে এআই ডেটাতে বৈচিত্র্য নিয়ে আলোচনা করা বড় ছবি দেখাবে না। এআই প্রশিক্ষণের ডেটার বৈচিত্র্যের সুযোগ এবং কীভাবে মানুষ এবং এআই একসাথে এই সংকটকে প্রশমিত করতে পারে তা সম্পূর্ণরূপে বোঝার জন্য, Shaip এ ইঞ্জিনিয়ারদের কাছে পৌঁছান. আমাদের বিভিন্ন এআই ইঞ্জিনিয়ার রয়েছে যারা আপনার এআই সমাধানের জন্য গতিশীল এবং বৈচিত্র্যময় ডেটা সরবরাহ করতে পারে।


